Azure Training In Hyderabad
With
100% Placement Assistance
- Best course to get into IT from non IT
- Job oriented Training
- Online Classes with Daily Recordings
- Resume creation support
- Expert Trainers with 10+ years Exp
- Mock Interviews
- Interview Questions
Azure Training In Hyderabad Online Details
| Trainer Name | Mr. Raghu |
| Trainer Experience | 10+ Years |
| Course Duration | 30 Days |
| Timings | Monday to Friday (Morning) |
| Next Batch Date | 15th April 2024; 11:30 AM IST |
| Training Modes | Online Classes |
| Call Us at | +91 98824 98844 |
| Mail Us at | azuretrainings.in@gmail.com |
| Demo Class Details | Get more details about Demo Class |
Azure Course Curriculum - Online classes
- Azure Portal
- Azure Powershell and CLI
- ARM Templates
- Azure Resource Manager (ARM)
- ASM vs ARM
- Creation of Azure Account
- Subscriptions and Accounts
- Role-Based Access Control (RBAC)
- Users and Groups
- Azure Policy
- Azure subscription cost management
- Azure security center
- Virtual Machine Planning
- Creating Virtual Machines
- Virtual Machine Availability
- Virtual Machine Extensions
- Managed and Unmanaged disk
- Additional Data disk
- Virtual Machine Scale sets
- Storage Accounts
- Azure Blobs
- Azure Files
- Azure Queues
- Azure Table
- Storage Security
- Azure Storage explorer
- Az copy
- Virtual Networks
- IP Addressing and Endpoints
- Azure DNS
- Network Security Groups and NIC
- CIDR calculation
- Public ip and private ip
- VNet Peering
- VNet-to-VNet Connections
- ExpressRoute Connections
- Site to site connections
- Point to site connection
- Azure Monitor
- Azure Alerts
- Log Analytics workspace
- Network Watcher
- Application insights
- Data Replication
- File and Folder Backups
- Virtual Machine Backups
- SQL DB in azure vm backup
- Network Routing
- Azure Load Balancer
- Application Gateway
- Azure Traffic Manager
- Azure front door
- Azure Active Directory
- Azure AD Connect
- Azure user management
- Multi-Factor Authentication
- Azure AD Identity Protection
- Self-Service Password Reset
- App registrations
- Enterprise applications
- SSO (Single sing on)
- Compare B2B with B2C
- App Service Environments
- App Service Plans
- Virtual Network Integrations
- Hybrid connections
- Creating App Service Web App
- Managed Identity
- Key Vault
- Azure Disk Encryption
- Automation Account
- Runbooks
- Update Management
- Scheduling patching
- Business Continuity and Disaster Recovery (BCDR)
- Replication of Azure VMs to different Regions
- Failover of Azure VMs
- Disaster Recovery for Apps
- Onprem physical vm migration to Azure
- Onprem Hyper-v vm migration to Azure
- AWS to Azure
Key Features Of Azure Training in Hyderabad
- Get real-time exposure with live practical demonstration of the subject matter
- Get top notch training from trainers with 10+ Years Experience and certified Instructors with industry credibility.
- Learn to manage and create Azure Subscriptions with hands-on application
- Deploy VMs with ARM Templates as a part of your project assistance
- Participate in our placement assistance program with access to top Azure Admin interview questions
- Get Microsoft Azure Az 104 certification and exam prep support to clear the exam in the first attempt
- Get a free demo & introductory session with trainers
- 500+ candidates trained and placed by Azure Trainings in the last 8 months.
- Attend 30+ hours of live theoretical training and 15+ hours of lab sessions
- Learn to migrate Data using Azure storage explorer and manage storage permissions.
- Though we don't guarantee you a job. But we market your resume to all our clients and associates to track better opportunities for you.
- Azure Training in Hyderabad everyday class recordings will be emailed to you through our LMS platform with lifetime accessibility.
- Azure admin manages cloud services, ensuring smooth operations, security, and optimal performance in Microsoft Azure environments.
- Yes, a fresher can become an Azure administrator with proper training and certification. Acquire Azure skills for a rewarding career.
What is microsft azure?
- Azure is a platform for cloud computing that gives users access to a variety of cloud resources and services.
- Azure will provide the services such as data transformation, storage, and many more.
- Azure provides an easy way to gather data, analyze it, and use various tools and methods to enable businesses.
- Microsoft Azure is used by nearly 80% of Fortune 500 companies.
About Azure Training in Hyderabad

We offer you the best Azure Admin Training In Hyderabad and our aim is to bring out the fullest potential of our students by teaching them the most in-demand cloud computing services. We train our students to develop, handle and deploy various web applications on the Azure cloud platform. Making sure that he is capable of handling the Roles & Responsibilities of an Azure administrator.
Fundamentals of Azure like Azure active directory, Azure policy, Role-Based Access Control (RBAC), Azure policy, Azure subscriptions, and Azure PowerShell are effectively taught. Live projects and practical training sessions are our specialties.
Looking to ace the azure game?
Well, you are at the right place. At Azure Admin Training In Hyderabad, we function with a set of highly certified trainers who train the students using various industrial techniques.
We involve students in projects that give them real-time experience and practice. By the end of the Azure Admin Training In Hyderabad, you will also acquire proficiency in VPN Gateways, Azure Storage, Blob Containers, and app service plans.
Our 30 day Azure Trainings program will not only enable you to learn the Azure Admin Training in Hyderabad course but will also make you a skill full and confident individual. You will walk out as a qualified Azure Trainings with higher chances of getting placed in MNCs.
We are the leading azure training institutes in Hyderabad with a remarkable success rate in the business.
To become an Azure administrator, gain proficiency in Azure services, earn relevant certifications, and gain hands-on experience.
Azure Training in Hyderabad Online Course Includes
- 30+ Hours of Live training.
- Daily 1 Hr of Online training with Lab Sessions
- Premium Whatsapp group support after admission
- AZ 104 & AZ 900 Certification Oriented Curriculum
- Practical Online Lab Sessions
- Free Demo & 2 more introduction classes for Free
- Live Doubt Clarifications after each session
- Real-time Project exposure with business Use cases
Modes of Azure Admin Trainings
ClassroomTraining
Azure trainings provides you with in-class training facilities for all course related to Azure including Azure DevOps, Azure Data factory & More.
Azure Training Online
Our online sessions conducted by our expert trainers are very interactive. You can join our Azure online training sessions from anywhere in the world at your own convenience.
Why Choose our Azure Training Program?
The Azure Admin training conducted by our experts will help you to become skilled Azure Administrator and make you competent in this field. Here’s the reasons why you choose us for Azure Admin Training in Hyderabad.
Lifetime Study Material
Get lifetime access for our study material and LMS by enrolling our Azure Admin training course.
Flexible Timings
You will get the advantage of flexible timing at Azure Admin Trainings, which will make it easy for you to join the class at their own convenience.
Hands-On-Training Experience
You will get the complete live practical real-time experience of Azure Admin Training with Interactive sessions and practice oriented concepts.
Student diaries
We have trained over 100+ students in Azure Admin Training with 70+ Students got placed successfully.
Affordable Fees
Our course fees for Azure Admin Training is very affordable with no extra charge.
Expert Trainer
We have a team of professional and certified Azure expert trainers with 10+ years of experience as an IT Professional on different platforms.
Updated Syllabus
Our syllabus has updated concepts of Azure Admin Training data to keep our students informed and industry ready.
Certifications
We provided certifications after compilation of the course which will help you for your resume makeing.
Placement Support
Azure Training In Hyderabad will provide a 100% guaranteed placement assistance for all our trainees. We also organize various programs to improve the skill and confidence of our students in the industry. Our Mock interviews preparations, job-counseling sessions, Q&A sessions help our students to crack any job interview and get placed in good organizations.
Students reviews
What do students say about our Azure Training In Hyderabad
Microsoft Azure Administration Certifications ( AZ104 ) details
AZ104 is the microsoft azure administration certification test with an Beginner to intermediate difficulty level when compared to other Microsoft certification exams.
Azure certified admins can earn competitive salaries, ranging from $70,000 to $120,000 annually, depending on experience and location.
Az104 exam generally consists of questions from 5 modules listed below.
- Module: Manage Azure identities and Governance (15-20%).
- Module: Implement and Manage Storage (10-15%)
- Module: Deploy and Manage Azure Compute Resources (25-30%)
- Module: Configure and Manage Virtual Networking (30-35%)
- Module: Monitor and backup Azure Resources
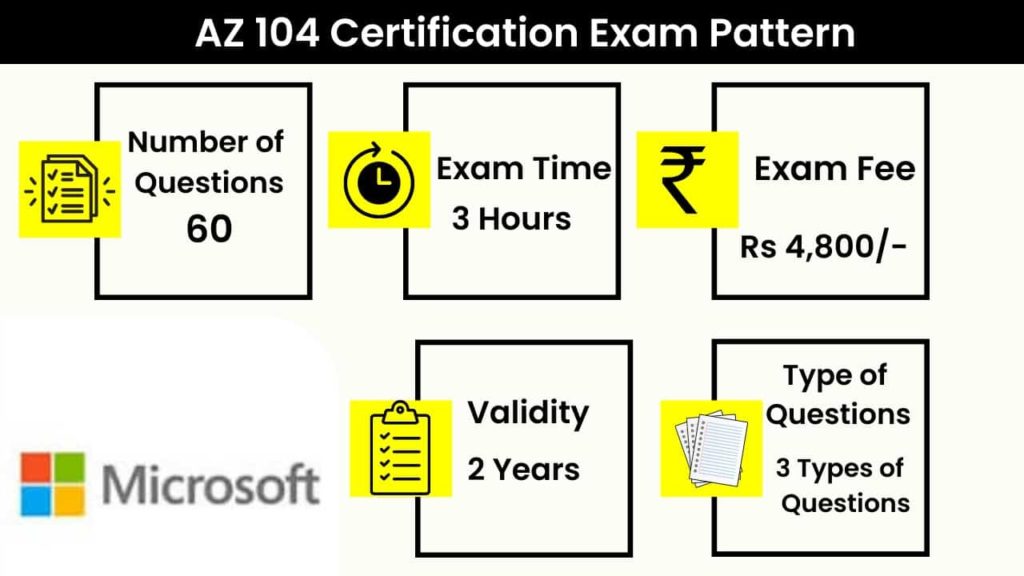
Azure Admin AZ 104 Certification Exam Pattern
- Number of Questions: 60 (around 60)
- Exam Time: 3 hours.
- Exam Fee: 4,800Rs in India
- Validity: 2 Years.
- Type of Questions: multiple-choice questions, Yes/No type of questions, hands-on and case studies. with singular or multiple.
Our Expertise
Benefits of Enrolling this Azure admin Training in Hyderabad
- Live Projects
- Azure Training Certification
- Backup Class
- Job Oriented Sessions
- Mock Interviews
- Azure Placement Program
Career Opportunities in Post Azure admin Training
- Al Engineer
- Security Engineer
- Data Engineer
- Data Scientist
Market Trend in Azure Administrators
- The demand for Azure Administrators is increasing as more companies adopt cloud-based technologies and solutions.
- A report by LinkedIn found that cloud computing and IT infrastructure skills, including Azure Administration, are among the top skills sought after by employers. With The Azure Training In Hyderabad .
- The global market for Azure Administration is expected to grow at a CAGR of over 27% during the forecast period of 2021-2026 according to Markets and Markets.
- As more businesses shift to cloud-based services, the demand for Azure Administration professionals is expected to continue to rise, leading to a shortage of skilled professionals in the field.
- The average salary for an Azure Administrator in the United States is around $92,000 per year, according to PayScale.
- Automation and DevOps are becoming increasingly important in Azure Administration, with a focus on streamlining infrastructure management and minimizing downtime.
- Security and compliance are top priorities for Azure Administrators, with a focus on ensuring the security and compliance of Azure resources.
- Azure Administration certifications, such as the Microsoft Certified: Azure Administrator Associate, are becoming increasingly important for demonstrating expertise and credibility in the field.
After Completion of this Azure Admin Training In Hyderabad
- Understanding the concepts of Cloud computing and its need.
- Get to know the different types of storage such as Blocks, Tables, and Line.
- Learn how to manage the app and how to use it.
- Learn about the creation, production and management of Visual Equipment and Virtual Network. etc..
- Mock Interviews
- Azure Placement Program
Prerequisites to Learn Azure Admin Course
- Basic knowledge of operating systems.
- Understanding of Virtualization.
- Basic Understanding of Networking
- Basic knowledge of any programming language.
- Good knowledge in Statistic.
Our Courses


Azure Training in Hyderabad Ameerpet
Green House, #202, Satyam Theatre Rd, Ameerpet, Hyderabad, Telangana 500016
Azure Training in Hyderabad KPHB
806, 8th Floor, Manjeera trinity Corporate, Besides Manjeera Cinepolis mall, KPHB Colony, Kukatpally, Hyderabad. 500072
Frequently Asked Questions;
Azure Administration is the process of managing and maintaining Azure resources, including virtual machines, databases, storage, and networking.
The key skills required to become an Azure Administrator include technical skills such as knowledge of Windows Server, Active Directory, SQL Server, PowerShell, and Azure platform services, as well as soft skills such as communication and collaboration.
You can gain experience in Azure Administration by working with an experienced Azure administrator, learning through online resources, and participating in community events.
You can stay up-to-date on the latest developments in Azure Administration by continuously learning new skills and staying informed about new technologies and industry developments.
The job outlook for Azure Administrators is strong, with high demand for skilled professionals in this field. Salaries for Azure Administrators are also competitive.
Azure admin salary in India is for cloud engineer ₹ 3,49,188 per year Development Operations Engineer ₹ 8,73,254 per year.
Yes, we do provide a demo session before every Azure Admin training in Hyderabad where you can clarify all your doubts before the enrolment.
We work for 100% student satisfaction, however, if you are not satisfied with Azure Admin training in Hyderabad we will provide you with additional specialized training.
Common challenges faced by Azure Administrators include security, complexity, cost management, migration, monitoring, automation, and skills gaps.
Azure certification costs in Hyderabad vary. Prices range from INR 5,000 to INR 30,000 or more, depending on the course and training provider.