Data Flow In Azure Data Factory

What is Polybase in Azure Data Factory?
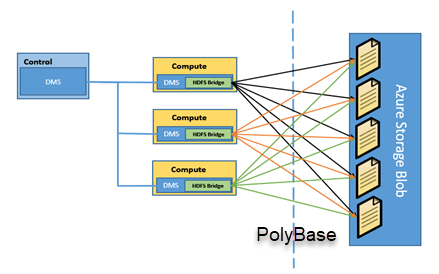
- Azure Data Factory is a cloud-based data integration service from Microsoft that allows businesses to move, transform, and manage data from various sources.
- One of the key features of Azure Data Factory is its Data Flow capability, which provides a visual interface for building data transformation logic without the need for advanced coding skills.
- Data Flow in Azure Data Factory is a graphical data transformation tool that allows users to design, build, and execute data transformation logic using a drag-and-drop interface.
- The data flow in Azure Data Factory is based on Apache Spark, a fast and scalable open-source data processing engine.
- This means that you can process large volumes of data quickly using the Data Flow toolset.
- Additionally, you can use Azure Databricks to run complex transformations that require machine learning or advanced analytics.
- With Data Flow, users can easily transform data from various sources, including on-premises and cloud-based data stores, into a format that can be easily consumed by downstream applications or analytical tools.
- Data Flow in Azure Data Factory works by providing a set of data transformation components that can be connected together to create a data flow pipeline.
- These components include sources, transformations, and sinks, which are used to extract, transform, and load data respectively.
- Data Flow in Azure Data Factory is a powerful tool that companies can use to transform raw data into formats easier for downstream systems to consume.
- With its drag-and-drop interface and range of data transformation components, Data Flow makes it easy for users to create complex data transformation pipelines without the need for advanced coding skills.
Types of Data Flows in Azure Data Factory
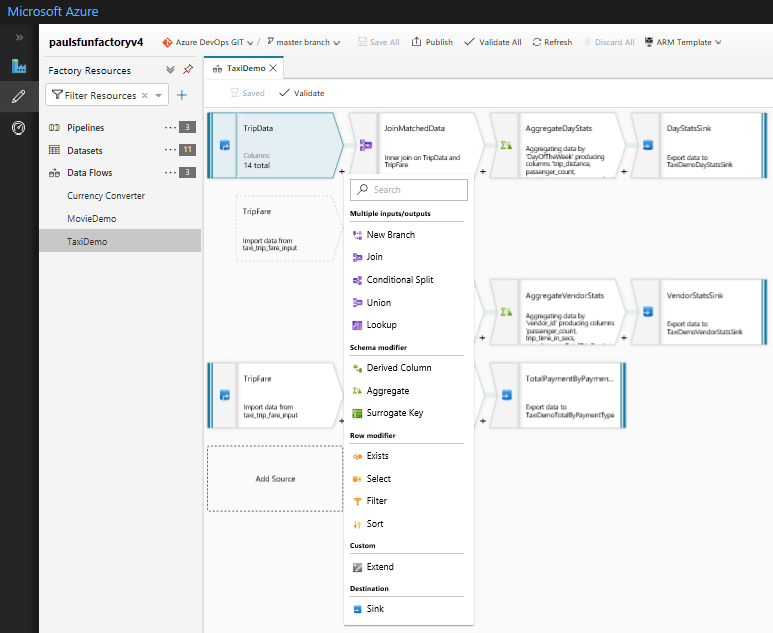
- Azure Data Factory provides two types of Data Flows: Mapping Data Flow and Wrangling Data Flow.
Mapping Data Flow
- Mapping Data Flow is a visual data transformation tool that allows users to design, build, and execute data transformation logic using a drag-and-drop interface.
- It is a fully managed, serverless data integration service that allows users to perform complex data transformations at scale.
- Mapping Data Flow is best suited for scenarios where data transformations are well-defined and static.
- Mapping Data Flow in Azure Data Factory is based on a set of data transformation components that can be connected together to create a data flow pipeline.
- These components include sources, transformations, and sinks, which are used to extract, transform, and load data respectively.
- Sources: Data sources are the starting point of a data flow pipeline in Mapping Data Flow. These can include various types of data stores such as Azure SQL Database, Azure Blob Storage, and Azure Data Lake Storage.
- Transformations: Transformations are used to modify the data as it flows through the pipeline. Azure Data Factory provides a range of transformation components such as aggregations, joins, and filters that can be used to manipulate data.
- Sinks: Once the data has been transformed, it needs to be loaded into a destination data store. Sinks are used to load data into destinations such as Azure SQL Database, Azure Blob Storage, or Azure Data Lake Storage.
Features of Mapping Data Flow
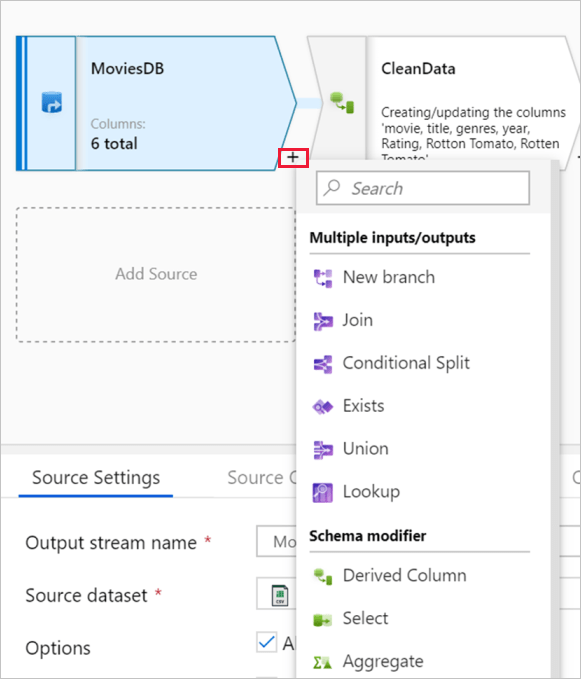
- Data Preview: Data Preview allows users to preview the data as it flows through the data flow pipeline. This allows users to quickly identify any issues with the data transformation logic and make changes before executing the pipeline.
- Debugging: Debugging in Mapping Data Flow allows users to step through the data flow pipeline and inspect the data at each stage of the pipeline. This is useful for identifying any issues with the pipeline and fixing them before executing the pipeline.
- Expressions: Expressions in Mapping Data Flow allow users to create dynamic data transformation logic that can be applied to data as it flows through the pipeline.
How to Create Data Flow In Azure Data Factory?
Step 1: Create an Azure Data Factory instance
To create a Data Flow in Azure Data Factory, you first need to create an Azure Data Factory instance. Follow these steps to create an instance:
- Go to the Azure portal.
- Click on the “Create a resource” button and search for “Data Factory”.
- Select the “Data Factory” option and click on the “Create” button.
- Fill in the required details, such as the name of the instance, subscription, resource group, and location.
- Click on the “Create” button to create the instance.
Step 2: Create a new pipeline
Once you have created an Azure Data Factory instance, you need to create a new pipeline to define the data flow. Follow these steps to create a new pipeline:
- In the Azure portal, navigate to your Data Factory instance.
- Click on the “Author & Monitor” button to open the Data Factory UI.
- Click on the “Author” tab to open the Authoring UI.
- Click on the “+” button and select “Pipeline” to create a new pipeline.
- Enter a name for the pipeline.
Step 3: Add a Data Flow activity
After creating a new pipeline, you need to add a Data Flow activity to define the data transformation logic. Follow these steps to add a Data Flow activity:
- In the pipeline canvas, click on the “+” button to add a new activity.
- Select the “Data Flow” activity from the list of available activities.
- Enter a name for the Data Flow activity.
Step 4: Configure the Data Flow activity
Once you have added a Data Flow activity to the pipeline, you need to configure it to define the data transformation logic. Follow these steps to configure the Data Flow activity:
- Click on the Data Flow activity to open the Data Flow editor.
- In the Data Flow editor, click on the “+” button to add a source dataset.
- Select the data source that you want to use from the list of available data sources.
- Configure the source dataset by entering the required details such as the connection string, table name, and columns.
- Click on the “+” button to add a sink dataset.
- Select the sink dataset that you want to use from the list of available data sources.
- Configure the sink dataset by entering the required details such as the connection string, table name, and columns.
- Add any required transformations by dragging and dropping transformation components onto the canvas and connecting them together.
- Preview the data and validate that the transformations are working as expected.
- Save and publish the Data Flow.
Step 5: Execute the pipeline
Once you have created and configured the Data Flow activity, you can execute the pipeline to run the data transformation logic. Follow these steps to execute the pipeline:
- Click on the “Publish All” button to publish the pipeline to the Data Factory instance.
- Click on the “Monitor & Manage” button to open the Monitoring UI.
- Select the pipeline that you want to execute.
- Click on the “Add Trigger” button to add a new trigger.
- Select the trigger type and configure the trigger details.
- Click on the “Create” button to create the trigger.
- Wait for the trigger to execute and monitor the progress in the Monitoring UI.
Advantages of Data Flow in Azure Data Factory
- Ease of Use: Data Flows provides a drag-and-drop interface that allows users to easily create and execute data transformations without having to write any code.
- Scalability: Data Flows are built on top of Azure Databricks, which provides a scalable and distributed computing environment for processing big data. This allows users to process large datasets quickly and efficiently.
- Reusability: Data Flows allows you to create reusable data transformation logic that can be applied to multiple data sources. This can save time and effort when building complex data pipelines.
- Data Profiling: Data Flows includes built-in data profiling capabilities that allow users to analyze and understand their data before applying any transformations. This can help identify data quality issues and ensure that the transformations are applied correctly.
- Integration with other Azure services: Data Flows integrates with other Azure services such as Azure Synapse Analytics, Azure Data Lake Storage, and Azure SQL Database, allowing users to build end-to-end data pipelines that can process data across multiple services.
- Code Generation: Data Flows generates code in Apache Spark to execute data transformations, which can be used to troubleshoot issues or to automate the creation of Data Flows pipelines.
- Monitoring & Management: Data Flows provide a monitoring dashboard that enables developers and data engineers to monitor the performance of DataFlows in real-time, enabling them to quickly identify and troubleshoot any issues.
- Data Transformation Capabilities: Data Flows provides a wide range of data transformation capabilities, including filtering, sorting, aggregating, pivoting, and joining data from multiple sources. This makes it easy to transform data into the desired format for downstream analytics and reporting.
Limitations of Data Flows in Azure Data Factory
While Data Flows in Azure Data Factory has many advantages, there are also some limitations
- Limited support for complex custom logic: Data Flows provides a wide range of built-in transformations, but it may not support all the custom logic required for complex data transformation scenarios. In such cases, users can use other tools or write their own code in order to achieve the desired outcome.
- Limited support for non-structured data: Data Flows are designed primarily for structured data, and it may not be the best tool for processing unstructured data such as images or audio.
- Limited support for real-time data processing: Data Flows is designed for batch processing of large datasets, and it may not be the best choice for processing real-time data streams.
- Limited integration with third-party tools: While Data Flows integrates well with other Azure services, it may not integrate as easily with third-party tools or services.
- Limited control over data partitioning: Data Flows automatically partitions data based on the source and destination data stores, which may not always be optimal for performance.
- Limited support for debugging: While Data Flows does generate code, it can be difficult to debug issues when something goes wrong. Users may need to rely on logging and monitoring tools to troubleshoot issues.
- Additional cost: Data Flows is a premium feature in Azure Data Factory, and it may require additional licensing fees. This can be a drawback for Small Businesses.
Disadvantages of Data Flow in Azure Data Factory
The main disadvantage of Data Flow in Azure Data Factory is its inability to deal with concurrency and parallelism. The designers have not been able to give a better solution for this problem so far.
- It’s not easy to set up and requires a lot of time and technical knowledge
- In some cases, you have to use custom code to create pipelines
- You can only use Data Flow when creating data pipelines in Azure Data Factory
- Data Flow is not available as a standalone tool
- Visual Data Flow is not as powerful as PowerShell for complex scenarios
- Problems with the Data Flow in Azure Data Factory can cause Data Factory to fail completely or stall out.
- Data Flow is designed for a single task such as loading data from one or more sources into one or more targets.
- You cannot use Data Flow to perform multiple tasks at once, because it is designed to run one pipeline at a time.
- For example, you cannot use Data Flow to load data from Azure Storage Blobs into SQL Server and then update the data in those tables.
Conclusion
- In conclusion, Azure Data Factory’s Data Flows feature provides a powerful and user-friendly way to build data transformation pipelines.
- With its drag-and-drop interface, built-in data profiling, and support for a wide range of data transformations, Data Flows can help organizations process large datasets quickly and efficiently.
- One of the key benefits of Data Flows is its ease of use. With its drag-and-drop interface, users can quickly and easily build data transformation pipelines without the need for complex coding or scripting.
- Another advantage of Data Flows is its support for a wide range of data transformations. From simple data cleaning and filtering to complex aggregations and joins, Data Flows can handle a variety of data transformation tasks.
- This makes it a valuable tool for organizations that need to process large datasets quickly and efficiently.
- However, it is important to note that Data Flows does have some limitations.
- For example, it may not be suitable for real-time data processing or for tasks that require custom logic.
- Additionally, there may be additional licensing fees for certain features. As with any technology solution, it is important to carefully evaluate the requirements and limitations before making a decision.
- Overall, Data Flows is a valuable addition to any data integration or ETL workflow and can help organizations transform their data into the desired format for downstream analytics and reporting.
- By leveraging its ease of use, built-in data profiling, and support for a wide range of data transformations, organizations can streamline their data processing tasks and improve the accuracy and reliability of their output data.
Courses




FAQs;
Azure Data Factory is a cloud-based data integration service that enables you to create, schedule, and manage data pipelines. It provides a platform for building and managing data integration workflows between various data stores, on-premises and cloud, structured and unstructured data.
Data Flows in Azure Data Factory are graphical tools that enable you to build and manage data transformation pipelines. There are two types of Data Flows: Mapping Data Flow and Wrangling Data Flow. Mapping Data Flow is used for ETL (Extract, Transform, Load) operations for structured data, while Wrangling Data Flow is used for data preparation and cleansing of unstructured and semi-structured data.
Data Flows in Azure Data Factory offer several advantages such as easy-to-use interface, scalability, integration with Azure services, reusability, monitoring and management, code-free data transformation, and cost-effectiveness.
Data Flows in Azure Data Factory can be integrated with other Azure services such as Azure Databricks, Azure Synapse Analytics, and Azure SQL Database.
Data Flows in Azure Data Factory can be used with pay-as-you-go pricing models, which means that users only pay for the resources they consume.