ETL in Azure Data Engineering
A Complete Guide to ETL in Azure Data Engineering
ETL in Azure Data Engineering is the process of collecting, transforming, and loading data using cloud tools. In this guide, you’ll learn how ETL works in Azure, explore services like Data Factory, Synapse, and Databricks, and discover best practices to build secure and efficient data pipelines. You’ll also see the benefits, challenges, and future trends of ETL in Azure.
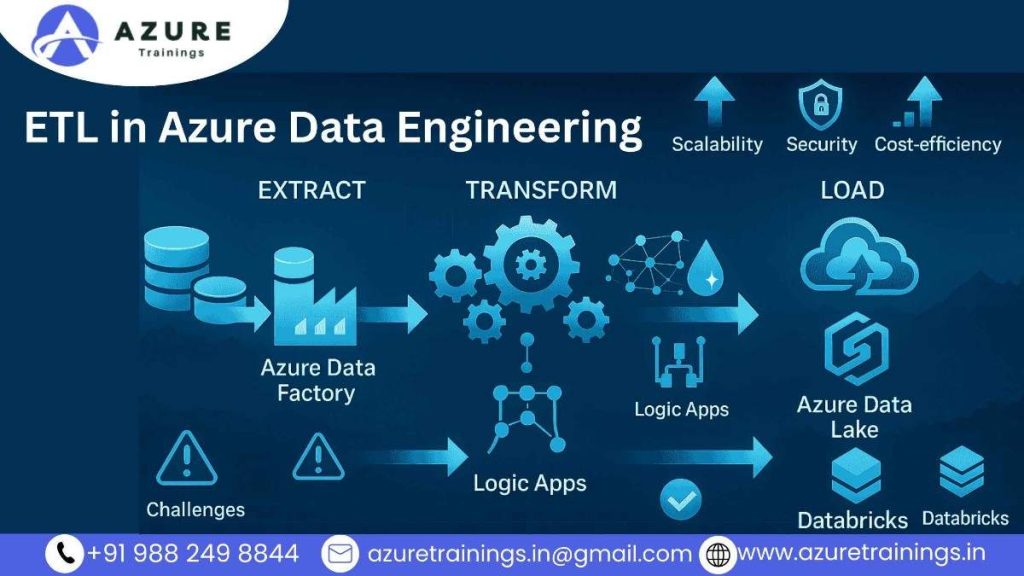
- In the world of Azure Data Engineering, ETL stands for Extract, Transform, Load. It is a process that moves data from different sources into a system where it can be stored and analyzed. ETL is one of the most important concepts in Azure-based data solutions because it enables engineers to prepare and move data in a structured and efficient way.
- Azure provides multiple tools to help data engineers build ETL pipelines in the cloud. These tools help automate the flow of data across systems, ensure quality and security, and scale with growing data volumes.
- Let’s explore what each part of ETL means in the context of Azure, and how it fits into modern cloud data engineering.
Extract in Azure :
The Extract step is the first stage of an ETL pipeline. In Azure, this means pulling data from various sources such as:
- On-premises databases (e.g., SQL Server, Oracle)
- Cloud-based databases (e.g., Azure SQL Database, Cosmos DB)
- Cloud storage (e.g., Azure Blob Storage, Data Lake Storage)
- External APIs or flat files like CSV, Excel, or JSON
Azure Data Factory (ADF) is the primary tool used to link and integrate with these data sources.. It offers over 90 built-in connectors, making it easy to pull data from virtually anywhere. Data engineers configure linked services in ADF to securely connect to data sources.
For on-premises sources, ADF uses a Self-hosted Integration Runtime, which allows secure access to internal systems.
Key extraction features in Azure:
- Built-in connectors
- Support for batch and incremental loads
- Integration with hybrid environments (cloud + on-prem)
Transform in Azure :
The Transform stage involves cleaning, filtering, joining, and enriching the extracted data. In Azure, transformation can be done in two main ways:
- Mapping Data Flows (ADF)
- A low-code, drag-and-drop interface for data transformation
- Allows operations like sorting, filtering, conditional splits, joins, and aggregations
- Executes on Azure’s Spark-based compute engine for scalability
- Azure Databricks or Azure Synapse Spark Pools
- Used when transformations are complex or require big data processing
- Engineers can write transformations using PySpark, Scala, or SQL
- Ideal for scenarios involving large datasets, machine learning preprocessing, or real-time enrichment
Azure supports schema drift handling, allowing pipelines to adjust when incoming data structures change. This is very useful when working with dynamic or semi-structured data like JSON.
Transformations in Azure are highly scalable and support parallelism, ensuring fast performance even for large datasets.
Load in Azure :
The Load step transfers the transformed data into a destination system where it can be stored or used for analysis. In Azure, common destinations include:
- Azure Data Lake Storage (ADLS): Ideal for storing raw or partially processed data
- Azure SQL Database: For structured, relational data
- Azure Synapse Analytics: For enterprise-scale data warehousing and reporting
- Power BI: For visualizing loaded data in dashboards and reports
ADF supports different loading strategies such as:
- Append loads: Adding new records
- Upserts: Updating existing records and inserting new ones
- Full loads: Replacing entire tables (used with caution)
Load operations can be scheduled, triggered by events, or manually executed. Azure ensures that data integrity is maintained throughout the process with built-in error handling and logging.
Why ETL Matters in Azure Data Engineering :
ETL is not just a technical process—it’s the foundation of reliable, automated, and scalable data architecture in Azure. Azure Data Engineers use ETL pipelines to:
- Move data from operational systems to analytical platforms
- Ensure consistency and quality across datasets
- Automate recurring data preparation workflows
- Support dashboards, business intelligence, and AI/ML models
Without an effective ETL process, data stays scattered, inconsistent, and difficult to trust.
In cloud environments like Azure, ETL pipelines are more flexible than ever. You can scale them automatically, manage them with infrastructure-as-code, and monitor them using Azure’s logging and metrics.
ETL Pipeline Architecture in Azure :
A typical ETL architecture in Azure might look like this:
- Source Layer: Data comes from SaaS apps, on-prem databases, cloud APIs, etc.
- Staging Layer: Raw data is temporarily stored in Azure Blob Storage or ADLS
- Transformation Layer: ADF data flows or Databricks scripts clean and prepare the data
- Presentation Layer: Data is loaded into Azure SQL, Synapse, or Power BI datasets
- Monitoring Layer: Logs and alerts via Azure Monitor, Log Analytics, or Application Insights
This modular approach helps Azure Data Engineers design pipelines that are reusable, maintainable, and scalable.
Key ETL Features in Azure :
- Parameterization : Makes pipelines reusable across environments (dev, test, prod)
- Triggering : Supports schedule-based and event-based pipeline execution
- Data Flow Debugging : Visual testing and breakpoint support in Mapping Data Flows
- Version Control : Integration with GitHub or Azure DevOps for pipeline management
- Security : Managed identities, private endpoints, and encryption for data in transit and at rest
Real-World Use Cases for ETL in Azure :
- Ingesting and transforming CRM data for reporting in Power BI
- Collecting sensor data and preparing it for real-time monitoring
- Consolidating sales data from global regions for executive dashboards
- Moving legacy data from on-premises systems to the Azure cloud
2. Origins and Evolution of ETL
Origins of ETL :
ETL started in the 1970s and 1980s when businesses began using computers to save large amounts of data. At first, data was stored in different systems that could not easily share information. For example, sales data might be in one database, while customer information was in another.
Companies soon realized that they needed a way to combine all this data to answer important questions. For instance, managers wanted to see how marketing expenses affected sales or which products were most profitable. But pulling data straight from operational systems was difficult and slow.
This need led to the idea of creating a separate storage area just for analysis. Data could be copied from day-to-day systems into this central place. To transfer the data, organizations had to take it out of each system, change it into a uniform format, and place it into the new storage system.
That process became known as ETL: Extract, Transform, Load.
In the early days, companies wrote their own programs and scripts to perform ETL. These custom solutions were often fragile and hard to maintain because every change in the source systems could break the process.
Early Data Warehousing
During the 1990s, the concept of the data warehouse gained widespread recognition. It refers to a specialized type of database designed specifically for reporting and analytical purposes.
Before data warehouses, teams often ran reports directly on transactional systems. This caused several problems:
- Reports slowed down the systems used for daily operations.
- Data was often incomplete or stored in inconsistent formats.
- It was difficult to keep a history of old records for long-term analysis.
With a data warehouse, companies could store cleaned, organized, and historical data in one place. This enabled analysts and business leaders to make more informed and effective decisions.
Data warehouses were usually relational databases, like Oracle, Teradata, or IBM DB2, designed for fast queries.
To fill these warehouses, businesses relied heavily on ETL. Here is how each step fit into early data warehousing:
- Extract: Data engineers took data out of source systems on a regular schedule (often nightly).
- Transform: They cleaned the data, fixed errors, matched formats, and sometimes aggregated it (for example, grouping daily sales by month).
- Load: The processed data was then saved into tables inside the warehouse.
At first, ETL jobs were run in batches, usually overnight or over weekends. This way, reports could be generated the next morning without slowing down operational systems.
Evolution of ETL :
As data grew in size and complexity, ETL had to change. In the late 1990s and early 2000s, businesses started using specialized ETL tools instead of writing custom scripts. Some popular tools were:
- Informatica PowerCenter
- IBM DataStage
- Microsoft SQL Server Integration Services (SSIS)
- Oracle Warehouse Builder
These tools allowed teams to create ETL workflows with visual interfaces, reducing the need to code everything by hand. They also made it easier to:
- Schedule jobs
- Monitor data flows
- Handle errors
- Document processes
Even so, these systems were mainly built for on-premises servers. Companies had to buy and maintain expensive hardware, install software, and hire specialists to keep everything running.
Another limitation was batch processing. Data loads typically happened once per day, so reports were always based on information that was at least a few hours old. Real-time analytics was rare and very complex to build.
As data volumes continued to increase, many companies found it hard to expand their ETL pipelines. Storage expenses went up, and processing big datasets became more time-consuming.
Transition to Cloud ETL :
In the 2010s, the rise of cloud computing began to reshape the ETL process once more. Platforms like Microsoft Azure introduced new ways to store and process data. Instead of buying hardware, companies could rent computing power and storage as needed.
This approach made ETL quicker, more affordable, and simpler to scale up. Cloud services provided benefits like:
- Elastic resources: You could quickly scale up to handle big workloads and scale down when not needed.
- Managed infrastructure: Azure and other cloud providers took care of servers, software updates, and security patches.
- More frequent data processing: Cloud ETL allowed near real-time updates, rather than just daily batches.
- Easy integration: Cloud platforms offer straightforward connections to a wide range of data sources and targets.
Within Azure, Azure Data Factory (ADF) emerged as the primary service for handling ETL tasks. ADF provided:
- A fully managed, cloud-native ETL solution.
- A visual designer for building pipelines.
- Over 90 connectors for common data sources.
- Support for both batch and real-time processing.
- Seamless connectivity with other Azure services such as Data Lake Storage, Synapse Analytics, and Power BI.
This shift meant that businesses no longer needed to spend months setting up hardware and software. They were able to begin on a small scale and expand gradually as needed. It also opened the door to modern analytics, including machine learning, big data processing, and advanced reporting.
How Cloud ETL Changed Data Engineering :
Moving ETL to the cloud made it more accessible to smaller companies, not just large enterprises. Teams could now:
- Automate complex data workflows with less effort.
- Pay only for the resources they used.
- Process and deliver data much faster.
- Combine structured and unstructured data more easily.
Over time, cloud ETL became the standard approach for most new data projects. Azure continues to add features that improve ETL performance, security, and monitoring.
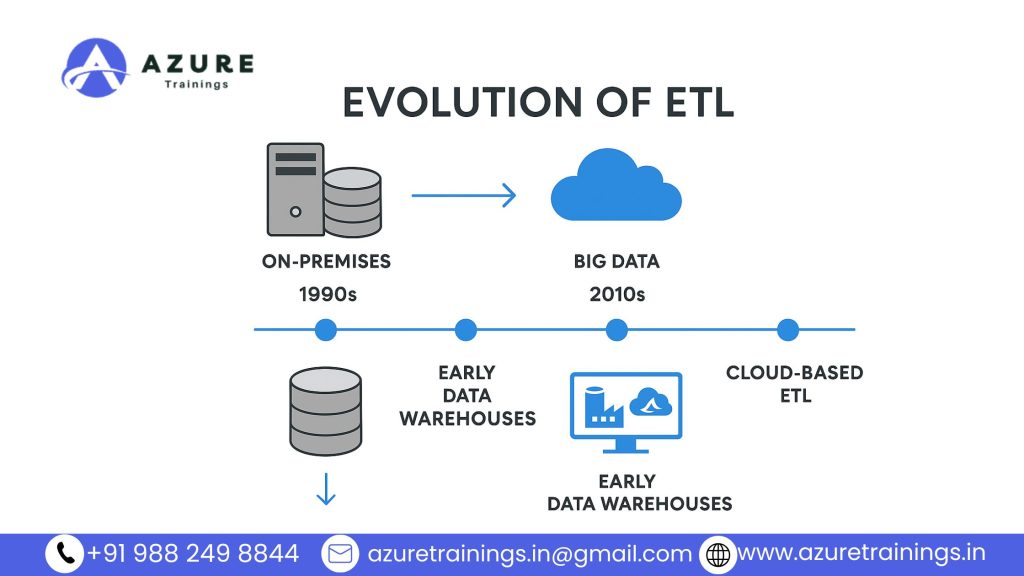
3. How ETL Works in Azure
Overview of Azure Data Factory and Other Tools :
In Microsoft Azure, ETL processes are mainly handled by Azure Data Factory (ADF). Azure Data Factory is a fully managed cloud service that lets you create, schedule, and monitor ETL pipelines without worrying about the underlying infrastructure.
Azure Data Factory provides a simple way to move data from many sources to your target storage or analytics system. It includes:
- Authoring tools: A web-based interface where you can build ETL workflows visually.
- Integration Runtime: The compute infrastructure that runs your data movement and transformation activities.
- Monitoring: Dashboards and logs so you can track progress and troubleshoot issues.
With ADF, you don’t need to write a lot of code. You can drag and drop activities onto a canvas to design the steps of your ETL process. This is sometimes called low-code or no-code ETL.
Besides Azure Data Factory, Azure also offers other tools that help with ETL:
- Azure Synapse Pipelines: Similar to ADF but integrated into Azure Synapse Analytics. It provides more features for big data and data warehousing scenarios.
- Azure Databricks: A fast, collaborative Apache Spark environment for more complex transformations and big data workloads.
- Azure Data Lake Analytics: Enables on-demand analytics tasks to run and manipulate data stored within Azure Data Lake Storage.
- SQL Server Integration Services (SSIS): If you’re currently using SSIS in an on-premises setup, you can move your packages to Azure with little to no modifications.
All of these services can work together depending on your needs. For example, you might use Azure Data Factory to orchestrate data movement and Azure Databricks for heavy data transformations.
Data Sources Supported :
One of the strongest advantages of Azure ETL is the large variety of data sources it can connect to. This means you can pull in data from almost anywhere without building custom connectors yourself.
Here are some of the common sources supported by Azure Data Factory:
Databases
- Azure SQL Database
- Azure Cosmos DB
- Azure Database for MySQL and PostgreSQL
- Oracle Database
- SQL Server (on-premises or in Azure VM)
- Teradata
Data Lakes and Storage
- Azure Blob Storage
- Azure Data Lake Storage Gen1 and Gen2
- Amazon S3
- Google Cloud Storage
SaaS Applications
- Salesforce
- Dynamics 365
- Marketo
- SAP
- ServiceNow
Files and Protocols
- SFTP servers
- REST APIs
- OData feeds
- HTTP endpoints
- Flat files like CSV, JSON, Parquet, Avro
In total, Azure Data Factory provides over 90 built-in connectors, and this list keeps growing. It’s also possible to develop custom connectors when required.
Azure Data Factory enables data ingestion through various methods, such as:
- Batch ingestion (scheduled loads)
- Incremental ingestion (only new or changed data)
- Event-based ingestion (triggered by new files appearing)
This flexibility makes it easy to build ETL pipelines that keep data fresh without overloading systems or creating duplicates.
How ETL Runs in Azure :
In Azure, an ETL process usually follows these steps:
- Connect to the Source
You create a Linked Service in ADF that securely connects to your data source. For example, you can set up credentials to connect to an Azure SQL Database or an SFTP server. - Define the Dataset
You tell Azure what data you want to pull. This could be a table, a folder in Blob Storage, or a file path. - Extract Data
Azure copies the data from the source system. This can be done all at once (full load) or in pieces (incremental load). - Transform Data
Data can be structured, adjusted, or combined to prepare it for analysis.- Mapping Data Flows: A visual tool inside ADF for transformations like joins, filters, and aggregations.
- Data Wrangling: For simpler, Excel-like data preparation.
- Custom code: Using Azure Databricks notebooks or stored procedures.
- Mapping Data Flows: A visual tool inside ADF for transformations like joins, filters, and aggregations.
- Load Data| :
Once transformed, the data is stored at the target location.. Common destinations include Azure Data Lake Storage, Azure Synapse Analytics, or Azure SQL Database. - Monitor and Manage
Azure provides tools to watch pipeline runs, retry failures, and see performance metrics.
Azure also supports parameterization, which means you can make pipelines dynamic—using variables for file names, table names, or connection strings. This makes it easy to reuse the same pipeline in different environments.
ETL vs. ELT in Azure :
In traditional on-premises environments, ETL was the standard approach:
- Extract data from the source.
- Transform it in a separate server or ETL tool.
- Load it into the target database.
This worked well when the transformation server had more computing power than the destination database. But in cloud environments like Azure, this has changed.
Azure supports both ETL and ELT. ELT stands for Extract, Load, Transform:
- Extract data from the source.
- Load it first into the target data store.
- Transform the data inside the target system.
This model has become popular in Azure for several reasons:
- Scalability: Cloud data warehouses like Azure Synapse can handle very large volumes of data.
- Performance: Transformations happen closer to the data, reducing movement.
- Cost efficiency: You avoid moving massive datasets between services.
Here’s the Difference Between ETL and ELT :
ETL | ELT |
Transformations happen before loading. | Transformations happen after loading. |
Often used with traditional databases. | Often used with cloud data warehouses. |
Requires separate compute for transformations. | Leverages compute power in the destination system. |
In Azure, ELT is often preferred when working with Synapse Analytics because you can use dedicated SQL pools to transform data at scale. However, ETL is still common when:
- You need to clean or filter data before loading.
- Source systems have sensitive data you don’t want to land untransformed.
- You are working with destinations that can’t process complex transformations.
Benefits of ETL and ELT in Azure :
Using Azure Data Factory and related tools gives you several advantages:
- Flexibility: Mix ETL and ELT as needed.
- Scalability: Easily expand to handle large volumes of data, ranging from terabytes to petabytes.
- Security: Use managed identities, encryption, and private networks.
- Low-code options: Build pipelines visually without writing much code.
- Integration: Easily connect to Power BI, Synapse, Databricks, and other Azure services.
- Cost Management: You’re charged based on actual usage, with the flexibility to increase or decrease resources as needed.
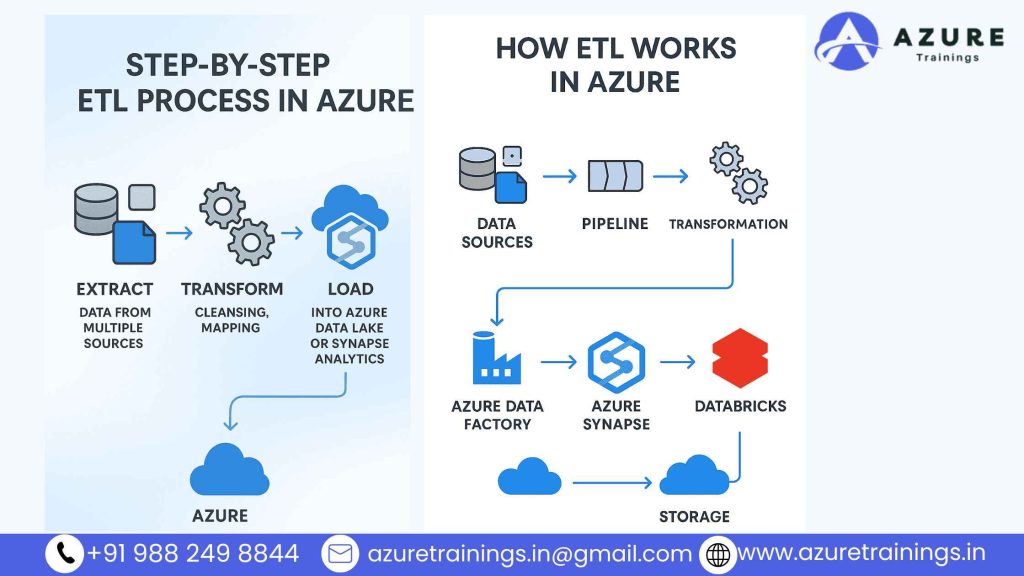
4. Step-by-Step ETL Process in Azure
In this section, you’ll learn how to build an ETL process in Azure step by step. We’ll keep it simple so anyone—even without a technical background—can follow along.
This process primarily utilizes Azure Data Factory (ADF), as it is one of the most widely used ETL tools within the Azure ecosystem. Let’s walk through each step in detail.
Step 1: Plan Your ETL Process
Before you build anything, you need to plan. Good planning saves time and avoids mistakes later.
Ask yourself these questions:
- What are my data sources?
For instance, sources like Azure SQL Database, Azure Blob Storage, Salesforce, or local on-premises databases can be used. - How often do I need to move data?
Is it daily, hourly, or in real-time? - What transformations do I need?
Will you clean data, merge tables, remove duplicates, or reformat columns? - Where will I load the data?
Maybe into Azure Data Lake Storage, Synapse Analytics, or Azure SQL Database.
Once you have answers, you can design your ETL pipeline.
Step 2: Create an Azure Data Factory
Azure Data Factory (ADF) is the main tool to create ETL pipelines in Azure.
How to set it up:
- In the Azure Portal, click Create a Resource.
- Search for Data Factory and click Create.
- Fill in basic details like Subscription, Resource Group, and Region.
- Click Review + Create, then Create.
After deployment, go to your Data Factory and click Author & Monitor. This opens the Data Factory Studio, where you build pipelines.
Step 3: Create Linked Services
Linked Services define the connections to both your data sources and target destinations.
To create a Linked Service:
- In Data Factory Studio, click Manage (the wrench icon).
- Choose Linked Services and click + New.
- Select the connector you need. For example:
- Azure SQL Database
- Blob Storage
- Amazon S3
- Oracle
- Azure SQL Database
- Enter connection details, such as server names, authentication types, and credentials.
- Test the connection to make sure it works.
- Click Create.
You need one Linked Service for each data source and destination.
Step 4: Create Datasets
A Dataset points to the specific data you want to work with—like a table or folder.
To create a Dataset:
- In the Author pane, right-click Datasets and click + New Dataset.
- Pick your data store type (e.g., Azure SQL Table, CSV file).
- Choose the Linked Service you just made.
- Choose or specify the file, folder, or table you need.
- Click OK.
You’ll need one dataset for each source and destination.
Step 5: Build the Pipeline
A Pipeline is the workflow that controls the ETL process.
- In the Author pane, click + Pipeline.
- Give your pipeline a name like DailyETLProcess.
This empty pipeline is where you’ll add activities to extract, transform, and load data.
Step 6: Extract Data
Copy Data Activity is used to extract data.
How to add it:
- In your pipeline canvas, drag Copy Data from the Move & Transform section.
- Click the activity to configure it.
- Under Source, select your input dataset.
- Choose options:
- Full data copy
- Incremental copy (only new or changed rows)
- Full data copy
- Under Sink, pick the staging area (for example, Blob Storage) or the final destination if no transformations are needed yet.
Example use case:
Copy daily sales data from Azure SQL Database to Azure Blob Storage in CSV format.
Step 7: Transform Data (Mapping, Cleansing)
If your data needs cleaning or formatting, you can use Mapping Data Flows.
How to create a Data Flow:
- In the Author pane, click + Data Flow.
- Give it a name like TransformSalesData.
- Inside the Data Flow canvas, click Add Source.
- Choose your input dataset.
Common transformation steps:
- Select: Pick only the columns you need.
- Filter: Remove rows with missing or invalid data.
- Derived Column: Create new columns or calculate values.
- Join: Combine multiple datasets.
- Aggregate: Summarize data, like totals or averages.
- Sink: Define where to write the transformed data.
Once you design your Data Flow, return to your pipeline:
- Drag Data Flow Activity into your pipeline.
- Connect it after the Copy Data Activity if you staged your data first.
- Choose your Data Flow.
Step 8: Load Data into Azure Storage or Analytics
Loading is the final step. You save your clean data in the destination.
Common destinations:
- Azure Data Lake Storage: Used to store both raw and transformed data files.
- Azure SQL Database: For structured tables.
- Azure Synapse Analytics: For big data warehouses.
If you already defined the sink in your Data Flow, Data Factory writes data there automatically.
If you used Copy Data without Data Flow, you can configure the Sink tab to pick your target dataset and set write behavior (append, overwrite, or upsert).
Step 9: Schedule and Trigger the Pipeline
After testing your pipeline, you can automate it.
Triggers can be:
- Schedule Trigger: Run every day at 2 AM.
- Event Trigger: Start when a new file arrives in Blob Storage.
- Manual Trigger: Run on demand.
To create a trigger:
- In the pipeline canvas, click Add Trigger > New/Edit.
- Choose the trigger type and configure the settings.
- Click OK and Publish All to save your work.
Step 10: Monitor and Troubleshoot
Once the pipeline runs, you need to monitor it.
- In Data Factory Studio, click Monitor (the clock icon).
- You’ll see a list of pipeline runs with status:
- Succeeded
- In Progress
- Failed
- Succeeded
- Click any run to see details, logs, and error messages.
- If something fails, you can rerun the pipeline after fixing the issue.
Tips for Better ETL Pipelines :
- Test each part separately before combining them.
- Use parameters so you can reuse pipelines for different datasets.
- Turn on logging to keep track of issues.
- Keep data transformations simple—complex logic may be better in Databricks or Synapse.
- Always document your pipelines, so others know how they work.
5. Key Azure ETL Tools and Services
Azure offers several tools to build, run, and monitor ETL processes. Each tool has different strengths, and they often work together to deliver end-to-end data solutions.
Azure Data Factory :
Azure Data Factory is a popular ETL tool in Azure. It runs in the cloud and helps you build data pipelines to move and change data.Key features include:
- Visual designer for building pipelines without much code
- More than 90 built-in connectors for different data sources
- Support for batch and incremental data loads
- Mapping Data Flows to clean and shape data
- Scheduling and monitoring options
Azure Data Factory is often used for copying data between systems, performing light transformations, and orchestrating data workflows.
Azure Synapse Pipelines :
Azure Synapse Pipelines are part of Azure Synapse Analytics, a platform that combines data integration, big data, and analytics.
Synapse Pipelines allow you to:
- Build ETL workflows similar to Data Factory
- Use Spark or SQL-based transformations
- Connect pipelines with both dedicated SQL pools and serverless SQL pools.
- Manage data movement and transformation within a single environment
This tool is a good choice for projects that need both ETL and advanced analytics in one place.
Azure Databricks :
Azure Databricks is a fast and collaborative data analytics platform that runs on Apache Spark technology. It is designed for big data processing and advanced transformations.
Main advantages include:
- High-speed data processing for large datasets
- Interactive notebooks that support writing code in languages like Python, SQL, Scala, or R
- Easy collaboration between data engineers and data scientists
- Auto-scaling clusters that adjust resources automatically
Databricks is often used for complex data preparation, machine learning, and scenarios where transformations need heavy compute power.
Logic Apps :
Azure Logic Apps is a workflow automation tool. Although it is not a traditional ETL service, it can help move and integrate data between systems.
Logic Apps can:
- Connect to hundreds of apps and services
- Automate tasks like sending notifications or creating records
- Run ETL pipelines automatically when specific events occur, such as when a file is added to storage.
- Combine data integration with business processes
Logic Apps work well when you need lightweight integrations or want to link ETL workflows to other processes like approvals and alerts
6. Advantages of ETL in Azure
Azure provides a strong platform for running ETL processes. Many organizations choose Azure because it offers clear benefits over traditional on-premises solutions. The following are some of the main advantages.
Scalability :
Azure ETL services can grow with your needs. When you work with large datasets, you do not have to buy more hardware or wait weeks to expand resources.With Azure, you can effortlessly adjust resources to scale up or down based on your needs..
For example, Azure Data Factory and Azure Synapse can process small daily loads or huge data volumes without changing your pipeline design. If your business collects more data over time, you can simply adjust the settings to handle higher volumes. This flexibility helps you keep performance high during busy periods without paying for extra capacity when you do not need it.
Azure’s scalability also means you can run multiple ETL pipelines in parallel. This allows you to process data faster and deliver results to your teams quickly.
Cost-Efficiency :
Running ETL in Azure can be more affordable than managing your own servers. In a traditional setup, you need to buy hardware, install software, and pay for maintenance and power. These costs can be high even if your data workload is small.
Azure uses a pay-as-you-go model. You pay only for the resources you use, such as compute power and storage. For example, when your ETL jobs run at night, you are charged for the processing time. When your pipelines are idle, you do not pay for unused capacity.
Azure also offers reserved pricing and discounts for longer-term commitments. This helps companies plan their budgets and avoid surprise expenses.
Because Azure services are managed by Microsoft, you save time and money on system updates, security patches, and monitoring. This lets your team focus on data instead of infrastructure.
Security and Compliance :
Ensuring data security is essential for every organization. Azure includes built-in security features that help keep your data safe during ETL processes.
Some of the main security benefits include:
- Encryption: Data is encrypted when stored and when moving between services.
- Access Controls: You can define who can access your data, pipelines, and storage accounts.
- Managed Identities: Services can connect securely without storing passwords in your code.
- Network Protection: You can use private endpoints and virtual networks to isolate your data.
- Monitoring and Alerts: Azure provides logs and alerts so you can detect unusual activity.
Azure also follows many compliance standards, such as GDPR, HIPAA, ISO, and SOC certifications. This makes it easier for companies in regulated industries to meet legal and industry requirements.

7. Challenges and Best Practices
Building and managing ETL pipelines in Azure comes with many benefits, but there are also some common challenges. Understanding these issues—and how to avoid them—can help you create better, faster, and more reliable data workflows.
Common Challenges :
Poor Data Quality
One of the most common problems in ETL projects is low-quality data. If source data has missing values, incorrect formats, or duplicate records, it can lead to wrong results after transformation. Relying on such data can harm reporting and decision-making.
Inefficient Pipeline Design
Some pipelines perform slowly because they load too much data at once or include unnecessary steps. Not planning the pipeline structure properly can lead to high costs, timeouts, or failures.
Lack of Monitoring
Many teams forget to set up alerts or logs for pipeline runs. Without monitoring, it’s hard to know when something goes wrong or how long a process took. This delay in detecting issues can cause problems in downstream reports or apps.
Hard-Coded Values
Using fixed values (like file names, paths, or dates) inside pipelines makes them harder to reuse or maintain. It also increases the chances of errors when environments change (such as moving from development to production).
Incomplete Error Handling
If a pipeline fails and there is no retry logic or error messaging, the process may stop completely without notifying anyone. This may lead to missing data or unsuccessful updates in the target systems.
Tips to Optimize Pipelines :
Use Incremental Loads
Instead of copying all data every time, configure pipelines to move only new or changed records. This reduces load time, saves costs, and avoids unnecessary processing.
Parameterize Everything
Where possible, use parameters and variables to make your pipeline flexible. For example, define file names, table names, or filter values as parameters so that you can easily run the same pipeline across different datasets.
Test with Small Data First
Run the pipeline on a small portion of data first to validate it before using the full production dataset. This helps catch logical or configuration errors early and saves time during development.
Monitor Regularly
Set up monitoring in Azure Data Factory through its built-in monitoring dashboard. Use alerts to notify your team when a job fails or takes longer than expected. This allows for faster issue resolution and more reliable data delivery.
Use Data Flow Caching
If you’re using Mapping Data Flows for complex transformations, enable staging and data flow caching when working with large volumes. This can significantly improve performance.
Separate Logic Clearly
Break the ETL process into smaller steps or pipelines—such as one for extraction, one for transformation, and one for loading. This modular design simplifies troubleshooting and enhances the readability of the pipeline.
Document Everything
Keep track of your pipeline’s purpose, steps, input and output datasets, and any business logic applied during transformations. Good documentation helps others understand and maintain your work over time.
Clean Up Resources
Unused Linked Services, datasets, or pipelines can clutter your environment. Regularly review and delete anything that’s no longer needed to keep your workspace organized and reduce confusion.

8. The Future of ETL in Azure
ETL in Azure is changing quickly as new technologies appear. Companies are moving beyond simple batch processing to faster, smarter, and more flexible data solutions. The future of ETL in Azure will be shaped by trends like serverless computing, artificial intelligence, and real-time streaming.
Serverless and Automation :
Serverless computing is becoming more popular because it removes the need to manage servers. In Azure, services like Data Factory and Synapse Pipelines already offer serverless options. This means you only pay for what you use, and Azure handles scaling, maintenance, and updates automatically.
In the future, ETL workflows will rely even more on serverless models. Pipelines will be easier to deploy without setting up infrastructure, and scaling up to process large data will take only a few clicks. Automation will also improve, allowing pipelines to run based on smart triggers and conditions without manual intervention. For example, data movement can start automatically when a new file is detected, or when a machine learning model signals that new data is ready.
These improvements will help teams build pipelines faster, reduce operational costs, and avoid the delays caused by manual processes.
AI-Driven Data Transformation :
Artificial intelligence is beginning to play a bigger role in ETL. In Azure, AI and machine learning tools can already analyze data quality, detect anomalies, and suggest ways to clean or enrich information.
Over time, AI-powered transformations will become more common. Instead of writing complex rules for data cleansing, teams will be able to use pre-trained models to standardize formats, fill in missing values, or classify records automatically. For example, AI could recognize product categories in free-text descriptions or match customer records across systems.
ETL tools are expected to have deeper integration with Azure Machine Learning and Cognitive Services in the future. This will let data pipelines apply predictions, sentiment analysis, and natural language processing as part of transformation steps. These capabilities will make data more useful for reporting and advanced analytics.
Integration with Real-Time Streaming :
Traditionally, ETL pipelines have been batch-oriented. They move data in scheduled jobs, like once per day or once per hour. But as businesses need more up-to-date insights, real-time data processing is gaining importance.
Azure offers built-in services such as Azure Stream Analytics and Event Hubs for managing streaming data. In the future, ETL will blend batch and streaming workflows more smoothly. This means you will be able to build hybrid pipelines that process historical data in batches while also handling live events instantly.
For example, an e-commerce company might process daily sales reports using batch ETL while also capturing clicks and orders in real time to update dashboards. This mix of batch and streaming ensures decision-makers always have the most current information.
New features in Azure Synapse and Data Factory will likely make real-time integration simpler, letting teams design pipelines that react immediately to data changes without extra development effort.

- ETL is the backbone of modern data engineering, and with Azure’s powerful ecosystem, building scalable, secure, and automated pipelines has never been easier. From its origins in traditional data warehouses to today’s cloud-native workflows, ETL continues to evolve. Azure services like Data Factory, Synapse, and Databricks make it easy for data engineers to build robust solutions that deliver value fast.
- Whether you’re starting out or upskilling, mastering ETL in Azure is critical for any cloud data engineer looking to thrive in a data-driven world.
FAQs
Extract, Transform, Load (ETL) is a widely used approach in Azure for integrating, processing, and moving data between systems. ETL plays a major role in Azure Data Engineering.
Azure Data Factory is the most commonly used ETL service in Azure.
In ETL, data is transformed before being loaded into the destination, whereas in ELT, raw data is loaded first and then transformed within the target system, such as Azure Synapse.
Yes, Azure Data Factory offers a low-code/no-code interface for building ETL pipelines using mapping data flows.
It uses pipelines, datasets, activities, and linked services to extract, transform, and load data between systems.
Azure mainly handles batch ETL processes, but it also enables near real-time data processing through services like Azure Stream Analytics.
Not necessarily. Azure Data Factory covers most ETL needs, but Databricks is useful for big data or complex transformations.
Azure provides strong security features including encryption, private endpoints, and role-based access control.
Yes, using self-hosted integration runtimes in Data Factory.
Knowledge of Azure services, data formats, SQL, and basic data modeling are essential.
Azure Data Factory charges based on pipeline activity runs, data movement, and compute used in data flows.
Azure supports CSV, JSON, Parquet, Avro, XML, and more.
Yes. Tools like Azure Synapse and Databricks are optimized for large-scale data transformations.
Yes. Azure Data Factory supports triggers to schedule pipelines at specific times or events.
It’s moving toward automation, real-time processing, and AI-assisted transformations.