Azure Synapse Analytics
In a data driven era where insights dictate innovation, businesses need advanced tools to handle massive datasets, perform complex analytics, and make real-time decisions. Azure Synapse Analytics, formerly Azure SQL Data Warehouse, is Microsoft’s powerful cloud analytics solution designed to combine big data and data warehousing into a single, seamless platform.This blog explores Azure Synapse Analytics in detail, its features, components, architecture, use cases, and best practices to help you understand how it can transform your organization’s data strategy.

What is Azure Synapse Analytics?
Azure Synapse Analytics is a powerful, unified analytics platform from Microsoft Azure that brings together enterprise data warehousing and big data analytics. It enables data professionals to seamlessly ingest, explore, prepare, manage, and serve data for business intelligence (BI) and machine learning (ML) applications all within a single environment.
With Azure Synapse, you can run queries on both structured (relational) and unstructured (non-relational) data using either T-SQL or Apache Spark. The platform deeply integrates with other Azure services such as:
- Azure Data Lake Storage (for scalable data storage)
- Power BI (for data visualization),
- Azure Machine Learning (for advanced predictive analytics),
and more enabling end-to-end data solutions.
2. Key Features of Azure Synapse Analytics
Azure Synapse Analytics is designed to deliver a comprehensive and scalable data analytics solution. It brings together data integration, enterprise data warehousing, and big data analytics in a unified environment. Below are the core features that distinguish Synapse Analytics:
1. Unified Analytics Platform
Azure Synapse combines data warehousing, big data processing, and data integration capabilities into a single platform. It supports both structured and unstructured data, enabling users to perform a full range of data operations from ingestion to reporting in one workspace.
- Query relational data using T-SQL or non-relational data using Apache Spark.
2. On-Demand Serverless Querying
With serverless SQL pools, you can run queries directly on data stored in Azure Data Lake without the need to provision compute resources in advance. Pay-per-query pricing model helps control costs.
- Supports querying large datasets without data movement or transformation.
3. Native Apache Spark Integration
Azure Synapse offers native Apache Spark integration, making it ideal for distributed data workloads. This is especially useful for advanced analytics and machine learning workloads.
- Supports multiple languages including Python, Scala, SQL, and .NET.
- The notebook feature in Synapse Studio supports seamless teamwork between engineers and data scientists.
4. Synapse Studio: Unified Development Interface
Synapse Studio is a web-based interface that offers a centralized workspace for authoring, managing, and monitoring analytics workflows.
- Develop SQL scripts, Spark notebooks, and data flows in one place.
- Visualize datasets and track pipeline executions.
- No-code and low-code development options for enhanced productivity.
5. Hybrid Data Integration with Synapse Pipelines
Synapse Pipelines, powered by Azure Data Factory, provide data integration and orchestration capabilities to build and manage ETL/ELT processes.
- Use a drag-and-drop interface to design workflows.
- Schedule and monitor pipeline executions with ease.
6. Seamless Power BI Integration
Azure Synapse offers native integration with Power BI, allowing users to create reports and dashboards directly from within the Synapse Studio environment.
- Share datasets with Power BI in real time.
- Enable business users to visualize data without needing to export or duplicate it.
- Create end-to-end analytics solutions from raw data to decision-ready insights.
7. Enterprise-Grade Security and Governance
Security and compliance are key strengths of Azure Synapse Analytics. The platform includes robust features to protect data and ensure regulatory compliance.
- Data is encrypted at rest and in transit.
- Role-Based Access Control (RBAC) helps enforce data access policies.
- Managed identities simplify secure service connections.
- Private endpoints and network isolation options prevent unauthorized access.
- Integration with Azure Purview enables data cataloging and governance.
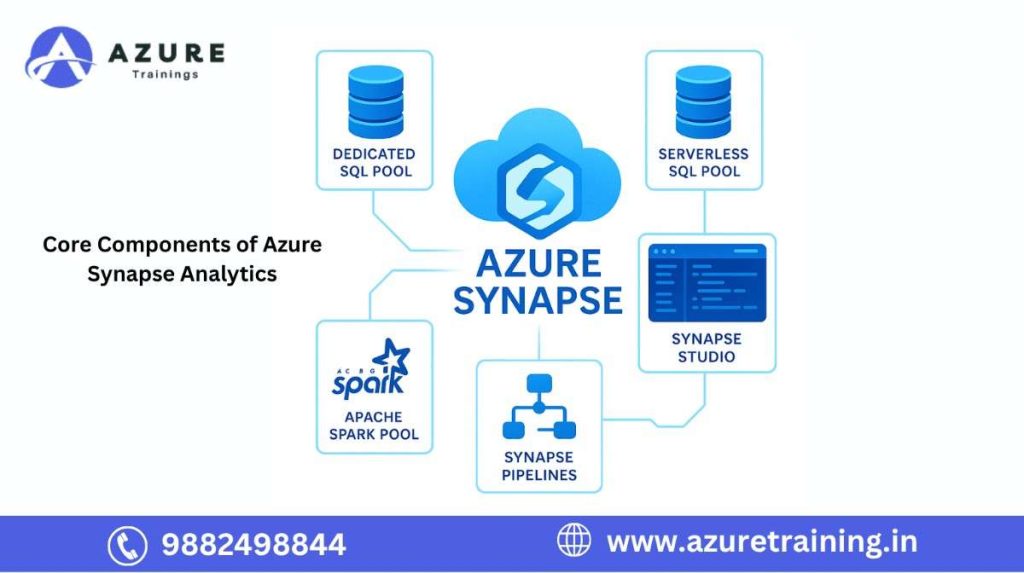
3. Core Components of Azure Synapse Analytics
Azure Synapse Analytics consists of multiple integrated components that support different data workloads, including structured data warehousing, big data analytics, real-time telemetry analysis, and data integration.
a. Dedicated SQL Pool
The Dedicated SQL Pool (formerly known as Azure SQL Data Warehouse) is a provisioned resource optimized for large-scale, high-performance data warehousing. It uses Massively Parallel Processing (MPP) to execute complex T-SQL queries efficiently across large datasets.
- Best suited for structured data and predictable, recurring workloads.
- Allows fine control over compute and storage resources.
- Supports indexing, partitioning, and materialized views for enhanced query performance.
b. Serverless SQL Pool
The Serverless SQL Pool allows you to query files directly in Azure Data Lake Storage using standard T-SQL without the need to provision or manage compute resources.
- Ideal for ad-hoc queries and data exploration.
- Supports querying data in formats like CSV, Parquet, and JSON.
- Uses a pay-per-query pricing model, reducing costs for infrequent use cases.
c. Apache Spark Pool
Azure Synapse provides built-in Apache Spark Pools for scalable big data processing. With these pools, users can perform machine learning, real-time analytics, and data transformations across distributed systems.
- Supports Python, Scala, SQL, and .NET for Spark development.
- Enables creation of Spark notebooks within Synapse Studio.
- Well-suited for data science, data engineering, and AI model training.
d. Synapse Pipelines
Synapse Pipelines offer code-free and code-based orchestration for data workflows, powered by Azure Data Factory integration. Users can design ETL and ELT processes using a visual drag-and-drop interface.
- Connects to over 90 data sources (on-premises and cloud).
- Enables batch and streaming data integration.
- Supports scheduling, monitoring, and automation of data pipelines.
e. Data Explorer Pool (Preview)
The Data Explorer Pool (currently in preview) is designed for high-volume telemetry and log analytics. It leverages the Kusto Query Language (KQL), optimized for real-time analytics on semi structured data.
- Ideal for analyzing logs, metrics, events, and time-series data.
- Complements other pools by handling high-ingestion and low-latency query needs.
- Designed for interactive exploration and diagnostics of streaming data.

4. Architecture of Azure Synapse Analytics
Azure Synapse Analytics is designed with a modular, layered architecture that supports a wide range of data processing and analytics workloads. This architecture allows organizations to build and manage data lakes, data warehouses, and data marts within a single, unified platform.Each layer in the architecture plays a distinct role, working together to deliver a seamless end-to-end analytics solution.
1. Ingestion Layer
This layer is responsible for collecting and ingesting data from various sources into the Synapse ecosystem. It supports different ingestion patterns, including:
- Batch ingestion using Azure Data Factory or Synapse Pipelines.
- Event-driven ingestion for near real-time analytics.
The ingestion layer ensures data flows efficiently into the storage layer, regardless of the format or velocity.
2. Storage Layer
The primary storage layer in Azure Synapse is Azure Data Lake Storage Gen2 (ADLS Gen2), which supports both structured and unstructured data. Key capabilities include:
- Hierarchical namespace for better file organization and performance.
- Tight integration with compute engines such as SQL, Spark, and Data Explorer.
3. Compute Layer
This is the processing engine of Azure Synapse, supporting multiple compute runtimes that can be used based on the workload type:
- SQL Pools:
- Dedicated SQL Pool: For high-performance, provisioned data warehousing.
- Apache Spark Pool:
- Supports distributed processing and multiple programming languages.
- Data Explorer Pool (Preview):
- Optimized for real-time telemetry and log analytics.
Each compute option is deeply integrated with the storage layer and can be used interchangeably depending on the use case.
- Optimized for real-time telemetry and log analytics.
4. Consumption Layer
This layer provides tools for data visualization, analysis, and downstream application integration. It includes:
- Azure Machine Learning: Enables advanced analytics and AI model training directly on Synapse data.
- Third-party BI tools: Connect via ODBC/JDBC or APIs for custom analytics solutions.
The consumption layer is where end users analysts, business users, data scientists interact with insights generated from the platform.
5. Benefits of Azure Synapse Analytics
Azure Synapse Analytics offers a range of powerful benefits that make it a compelling choice for modern data-driven organizations. Its architecture and integrated features are designed to improve efficiency, reduce complexity, and deliver insights faster.
1. Flexibility in Compute Options
Azure Synapse gives users the choice between on-demand (serverless) and provisioned (dedicated) resources, allowing teams to optimize cost and performance based on their specific workload requirements.
- Use serverless SQL pools for quick, ad-hoc queries without provisioning infrastructure.
- Choose dedicated SQL pools when predictable, high-performance compute is needed for large-scale analytics.
This flexibility allows teams to adapt quickly to changing data needs and project scopes.
2. High Performance with Massively Parallel Processing (MPP)
The platform uses Massively Parallel Processing (MPP) architecture to execute complex queries across large datasets efficiently. This results in:
- Faster query performance across petabytes of data.
- Reduced processing time for analytics and reporting workloads.
- Optimized data partitioning and workload distribution.
3. Scalable Architecture
It provides the ability to scale computing power and storage space separately, ensuring efficient resource utilization.
- You can increase or decrease compute power without affecting your data storage setup.
- Efficient resource allocation based on usage patterns and business growth.
- Cost control through elasticity and autoscaling options.
This makes Synapse suitable for both small-scale data projects and large enterprise-grade analytics systems.
4. Unified Data Platform
Synapse combines data integration, big data processing, data warehousing, machine learning, and reporting in a single interface eliminating the need for managing multiple tools.
- Reduces data movement between systems.
- Simplifies pipeline development and data management workflows.
This unified approach accelerates time-to-insight and improves operational efficiency.
5. Cost-Effective for Variable Workloads
With the pay-per-query pricing model in serverless SQL pools, Synapse is ideal for:
- Infrequent or unpredictable workloads.
- Exploratory data analysis.
- Proof of concept and testing scenarios.
Provisioned compute can be paused or scaled based on demand, helping organizations avoid unnecessary spending.
6. Enterprise-Grade Security and Compliance
Security is deeply embedded into Synapse Analytics. Microsoft ensures the platform meets the highest standards for data protection and governance.
- Data encryption at rest and in transit.
- Role-Based Access Control (RBAC) and managed identities for secure access.
- Compliance with global standards like HIPAA, ISO, SOC, GDPR, and more
6. Common Use Cases of Azure Synapse Analytics
Its ability to unify data storage, processing, and visualization in one platform makes it highly versatile.
a. Enterprise Data Warehousing
Azure Synapse serves as a robust enterprise-grade data warehouse where data from various operational systems—ERP, CRM, web apps, and more can be consolidated.
- Perform data ingestion, transformation, and modeling in one platform.
- Establish a single source of truth for business reporting and compliance.
- Enable historical data analysis and trend forecasting at scale.
This centralized approach improves data quality, governance, and accessibility across departments.
b. Advanced Analytics
With native support for Apache Spark and seamless integration with Azure Machine Learning, Synapse enables teams to build and deploy predictive analytics and machine learning models directly on the platform.
- Leverage Spark-based environments to explore datasets and train models.
- Use integrated pipelines to perform real-time analysis using trained models.
This capability supports data science teams in developing intelligent applications and AI-driven solutions.
c. Business Intelligence (BI)
Azure Synapse integrates directly with Power BI, enabling business analysts and decision-makers to build interactive dashboards without the need to move or duplicate data.
- Query data in place using serverless SQL pools.
- Empower self-service BI while maintaining centralized data control.
This tight integration ensures faster insights and better collaboration between data and business teams.
d. Streaming and Log Analytics
The platform supports real-time and near real-time analytics through Spark Streaming and Data Explorer Pools (using Kusto Query Language – KQL).
- Ingest data from sources like Azure Event Hub, IoT Hub, or Kafka.
- Analyze logs, telemetry, sensor data, and event streams.
- Detect anomalies, monitor performance, and respond to incidents quickly.
This use case is especially relevant for applications in IoT, cybersecurity, and operations monitoring.
e. ETL and ELT Pipelines
Azure Synapse Pipelines provide a low-code/no-code environment to build scalable ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes.
- Orchestrate workflows across multiple data sources and destinations.
- Automate data movement, cleansing, and transformation tasks.
This makes Synapse suitable for modern data integration projects where agility and efficiency are key.
7. Synapse Studio: The Control Center
Synapse Studio is the centralized, browser-based integrated development environment (IDE) for Azure Synapse Analytics. It provides a unified workspace for building, managing, and monitoring all components of a data analytics solution from data ingestion to reporting. Designed for ease of use and collaboration, Synapse Studio brings together multiple capabilities within a single interface, allowing data engineers, analysts, and data scientists to work together efficiently.
Key Capabilities of Synapse Studio
• Author SQL, Spark, and KQL Scripts
Users can write and execute queries in T-SQL for structured data, Apache Spark for big data and machine learning, and Kusto Query Language (KQL) for log and telemetry analytics. All script types are supported within a seamless interface.
• Design and Monitor Pipelines
With Synapse Pipelines integrated into the Studio, users can visually design ETL/ELT workflows, schedule data movement, and monitor job execution status all within the same workspace.
• Explore and Manage Datasets
The Data Hub in Synapse Studio allows users to browse and manage linked datasets across storage accounts, SQL pools, and other data sources. This helps in quickly understanding schema and data structures.
• Visualize Data with Power BI
Synapse Studio features built-in integration with Power BI, enabling users to build and share interactive dashboards without leaving the development environment. This accelerates the transition from data to insight.
• Run Notebooks (Similar to Jupyter)
Synapse supports notebooks with multiple language kernels (e.g., PySpark, Scala, .NET Spark), allowing data scientists and engineers to perform advanced data exploration, transformation, and modeling in a collaborative setting.
Collaboration Made Easy
By consolidating tools traditionally spread across multiple platforms, Synapse Studio significantly enhances productivity and streamlines collaboration. Whether it’s a data engineer building pipelines, a data analyst writing SQL queries, or a data scientist developing ML models, all can operate within a shared and cohesive environment.
8. Integration with the Azure Ecosystem
This connectivity enables users to build, deploy, and manage end-to-end data solutions within a unified cloud environment without the need to stitch together disparate tools or move data between platforms.
• Azure Data Lake Storage Gen2
Synapse is tightly coupled with Azure Data Lake Storage Gen2, serving as the primary storage layer for both structured and unstructured data. This integration supports:
- Hierarchical namespace for efficient data organization
- Direct querying of files using SQL Serverless and Spark
- Large-scale analytics with low-latency access
• Azure Blob Storage
In addition to Data Lake, Synapse supports Azure Blob Storage, allowing ingestion and processing of flat files, images, logs, and semi-structured data stored in blob containers.
• Azure Machine Learning
Azure Synapse integrates with Azure Machine Learning, enabling data scientists to:
- Access and transform data for model training
- Deploy predictive models directly within Synapse pipelines
- Perform model scoring at scale using Spark
This helps unify machine learning workflows with data engineering processes.
• Power BI
- Build and embed dashboards directly from Synapse Studio
- Visualize live data without needing to move or duplicate it
- Share insights with stakeholders in real time
This integration bridges the gap between data engineering and business intelligence.
• Azure Purview
- Automatically scan, classify, and label data assets
- Track lineage and data flow across the ecosystem
- Improve data discoverability and compliance
• Event Hubs and Stream Analytics
Synapse supports real-time analytics by integrating with Azure Event Hubs and Azure Stream Analytics:
- Ingest and analyze streaming data from IoT devices, applications, or telemetry systems
- Enable near real-time dashboards and anomaly detection
- Combine batch and streaming data in a unified analytics environment
Unified Azure Experience
These native integrations allow businesses to build end-to-end analytics and AI solutions entirely within the Azure environment. From data ingestion and processing to modeling, visualization, and governance, Synapse acts as the central control plane that brings all components together.
This reduces complexity, minimizes data movement, enhances security, and enables faster time-to-insight.
9. Pricing Model
Azure Synapse Analytics offers flexible and scalable pricing options designed to accommodate a variety of workloads and usage patterns. Whether your organization requires constant high-performance compute or occasional data exploration, Synapse provides cost models to suit both scenariosBelow are the three primary pricing models available in Synapse Analytics:
a. Dedicated SQL Pool (DWU-Based Pricing)
The Dedicated SQL Pool is designed for consistent, high-volume data warehousing workloads. It uses Data Warehouse Units (DWUs) as a measure of compute capacity.
- Billing Model: Charged per hour based on the number of DWUs provisioned.
- Use Case: Ideal for long-running, mission-critical workloads with predictable query patterns.
- Pause/Resume: You can pause the compute to stop charges when not in use, while data remains stored.
- Scalability: You can scale DWUs up or down as needed for performance tuning.
This model is suitable for enterprise environments where dedicated, always-on compute is required.
b. Serverless SQL Pool (Pay-Per-Query Pricing)
The Serverless SQL Pool allows you to run on-demand queries directly on files in Azure Data Lake Storage without provisioning any infrastructure.
- Billing Model: Charged based on the amount of data processed, typically per terabyte (TB).
- Use Case: Ideal for ad hoc analysis, exploratory queries, or workloads with infrequent usage.
- Cost Efficiency: You only pay for what you use there is no charge for idle time.
This option is optimal for organizations seeking flexibility and cost control without sacrificing performance.
c. Apache Spark Pools
Azure Synapse offers built-in Apache Spark pools for large-scale data transformation, machine learning, and stream processing.
- Use Case: Suitable for data engineering, AI model training, and parallelized data processing tasks.
- Auto-Scaling: You can configure Spark pools to scale automatically, helping manage costs.
This model allows data scientists and engineers to run distributed Spark jobs without managing the infrastructure manually.
10. Security and Compliance
Azure Synapse Analytics is built with enterprise-grade security features to help organizations protect sensitive data, ensure regulatory compliance, and maintain secure data operations across the analytics lifecycle. It integrates multiple layers of protection, monitoring, and control to safeguard both data and infrastructure.Below are the key security and compliance features offered by Azure Synapse:
1. Data Encryption (At Rest and In Transit)
All data in Azure Synapse is encrypted by default both at rest using Azure Storage Service Encryption (SSE) and in transit using Transport Layer Security (TLS).
- Helps protect data from unauthorized access or tampering.
- Supports bring-your-own-key (BYOK) and customer-managed keys (CMK) for enhanced control.
2. Network Isolation via Private Endpoints
Azure Synapse supports Private Link, allowing you to create private endpoints for secure, isolated access to Synapse resources over your virtual network (VNet).
- Prevents data exposure to the public internet.
- Enables segmentation and access control through network security groups (NSGs).
3. Identity and Access Management (IAM)
Access to Synapse resources is managed using:
- Managed identities: Securely connect to other Azure services without storing credentials.
- Role-Based Access Control (RBAC): Assign fine-grained permissions to users and groups based on roles.
- Azure Active Directory (Azure AD): Centralized identity management for authentication and authorization.
4. Auditing and Threat Detection
Azure Synapse supports activity auditing and security alerting features to monitor and respond to potential threats:
- Log user activity, query history, and resource access events.
- Detect unusual behavior or potential data breaches with built-in Advanced Threat Protection.
5. Data Masking and Classification
Built-in dynamic data masking allows administrators to hide sensitive data from unauthorized users at query time, without altering the underlying dataset.
- Useful for protecting fields like credit card numbers, personal identifiers, or financial data.
- Data classification tags help identify and label sensitive fields for governance and compliance tracking.
FAQ's
Azure Synapse Analytics is a cloud based analytics service from Microsoft that combines data warehousing and big data analytics into a unified platform.
That’s right. Azure Synapse is the modernized version of SQL Data Warehouse, designed to handle complex analytics, data science, and scalable integrations.
The main components are Dedicated SQL Pool, Serverless SQL Pool, Apache Spark Pool, Synapse Pipelines, and Synapse Studio.
While dedicated pools are reserved for steady, high-performance workloads, serverless pools enable querying without the need for prior resource allocation.
Yes. Azure Synapse has native support for Apache Spark for big data processing and machine learning tasks.
Synapse Studio is a browser-based integrated development environment for querying, transforming, and visualizing data within Azure Synapse.
Yes. Synapse can process and analyze unstructured data using Spark and serverless SQL, especially in formats like Parquet, JSON, and CSV.
Developers can utilize T-SQL, Spark SQL, Scala, Python, .NET, and Kusto Query Language within Azure Synapse.
Synapse Pipelines support the full lifecycle of ETL and ELT workflows, from development to automation and monitoring.
You can leverage Synapse Pipelines to design, automate, and oversee your ETL and ELT data processes.
Yes. Azure Synapse supports real-time analytics using serverless SQL, Spark, and integration with Azure Stream Analytics.
Yes. Data is encrypted at rest and in transit using Microsoft-managed or customer-managed keys.
Synapse supports various file formats, including CSV, JSON, Parquet, Avro, and Delta.
Azure Synapse offers deeper Azure ecosystem integration, built-in Spark support, and both on-demand and provisioned query options.
Pricing is based on usage of dedicated or serverless SQL pools, Spark pools, and storage.