Azure Data Factory Architecture

Introduction
In today’s cloud-driven world, data is at the center of every decision. Companies deal with large volumes of data, and they need a reliable, scalable, and secure way to move, transform, and store this data. Microsoft’s Azure Data Factory (ADF) offers a powerful solution to manage this.
This guide breaks down the Azure Data Factory architecture in simple, easy-to-understand language, making it ideal for:
- Beginners
- Data Engineers
- Cloud professionals
- Decision-makers
You’ll also discover real-world examples, job trends in India, detailed components, FAQs, case studies, and much more.
What is Azure Data Factory?
Azure Data Factory (ADF) is Microsoft’s cloud-based data integration service. It allows you to build data pipelines to move and transform data from multiple sources to your desired destination.
ADF helps companies :
- Extract data from various sources (SQL, Blob, APIs, etc.)
- Clean and transform the data
- Load it into reporting or analytics systems like Power BI or Azure Synapse
It supports both ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) approaches.
Why Azure Data Factory?
- Cloud-native: Fully managed by Microsoft
- Cost-effective: Pay only for what you use
- Scalable: Handle massive data loads
- Hybrid connectivity: Works with on-prem and cloud sources
- Low-code: Build pipelines with minimal code
- Secure: Integrated with Azure Active Directory and private endpoints
Overview of Azure Data Factory Architecture
At a high level, Azure Data Factory architecture consists of these main components:
1. Pipelines
A pipeline is a logical container of activities. It describes how your data moves and is processed step by step.
Example: A pipeline that extracts customer data from SQL, transforms it in a Data Flow, and stores it in Azure Data Lake.
2. Activities
Activities are the individual tasks in a pipeline. Types include:
- Copy Activity: Move data from source to destination
- Data Flow: Perform data transformation
- Web Activity: Call external APIs
- Stored Procedure Activity: Execute SQL commands
3. Datasets
A dataset represents your data’s structure and location. For example:
- A table in Azure SQL
- A folder in Blob Storage
4. Linked Services
These define connection information (credentials, URLs, etc.) to connect with data sources and compute environments.
5. Integration Runtime (IR)
This is the compute infrastructure used by ADF to move and transform data. Types include:
- Azure IR: For cloud-based movement
- Self-hosted IR: For on-prem sources
- SSIS IR: Run SSIS packages in Azure
6. Triggers
These start pipeline execution based on:
- Time schedules (hourly, daily, weekly)
- Events (file arrival, blob changes)
7. Control Flow
Allows conditional logic using:
- If Condition
- Switch
- ForEach loops
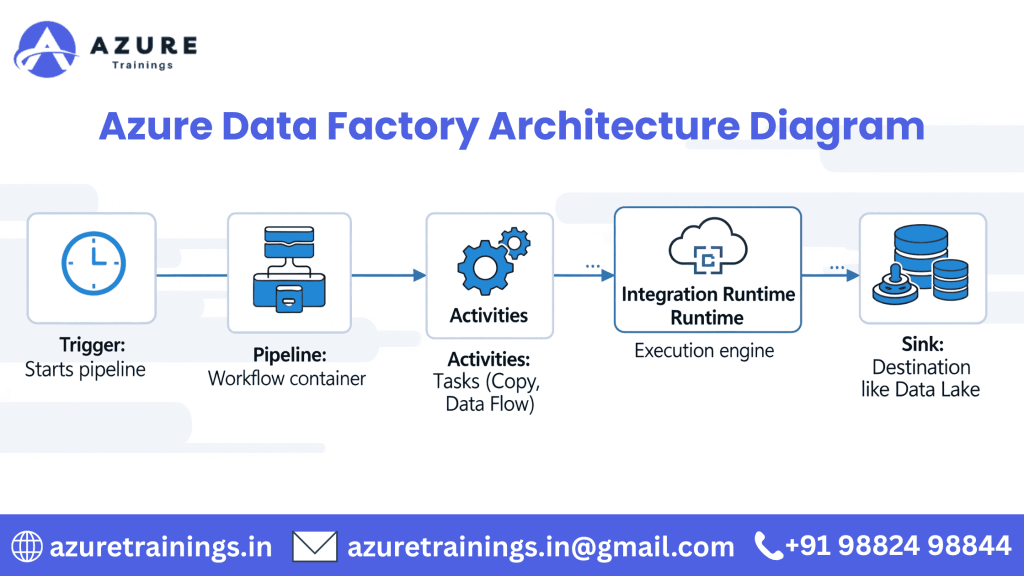
How Azure Data Factory Works (Data Flow)
- Trigger starts the pipeline (manual or scheduled)
- Pipeline begins execution
- Activities within the pipeline perform their tasks
- Integration Runtime moves/transforms the data
- Transformed data is saved to the target location (e.g., Azure Synapse)
Structured Representation of Azure Data Factory Components
Step-by-Step Data Flow in Azure Data Factory
┌──────────┐
│ Trigger │ → Starts the pipeline automatically when a specific time or event occurs
└────┬─────┘
▼
┌────────────┐
│ Pipeline │ → Orchestrates the sequence and logic of data tasks
└────┬───────┘
▼
┌──────────────┐
│ Activities │ ← Tasks like copy, transform, REST API calls, etc.
└────┬─────────┘
▼
┌────────────────────┐
│ Integration Runtime │ → Executes activities using Azure IR or Self-hosted IR
└────┬───────────────┘
▼
┌────────────┐
│ Sink/Output│ ← Final destination (Blob, Data Lake, Synapse, etc.)
└────────────┘
Component Notes for the Diagram:
Component | Role |
Trigger | Starts the pipeline automatically or on demand |
Pipeline | Container for all activities and workflow logic |
Activities | Copy, Data Flow, Web call, Stored Procedure, etc. |
Integration Runtime | The compute engine that runs the activities |
Sink/Output | Final destinations can include services like Azure Data Lake, Azure SQL Database, Blob Storage, and more. |
Example Use Case (Flow):
A scheduled trigger runs every morning →
The pipeline starts and reads sales data from on-prem SQL →
Data is copied and transformed in a mapping data flow →
Data is stored in Azure Data Lake →
Power BI dashboards are refreshed.
Real-Life Example (Case Study)
Company: Large Retailer in India
Problem: Manually syncing sales and inventory data across systems
Solution: ADF pipelines to automate data movement from POS systems to Azure SQL, then to Power BI
Result:
- Reduced reporting time from 6 hours to 20 minutes
- Improved forecasting by 70%
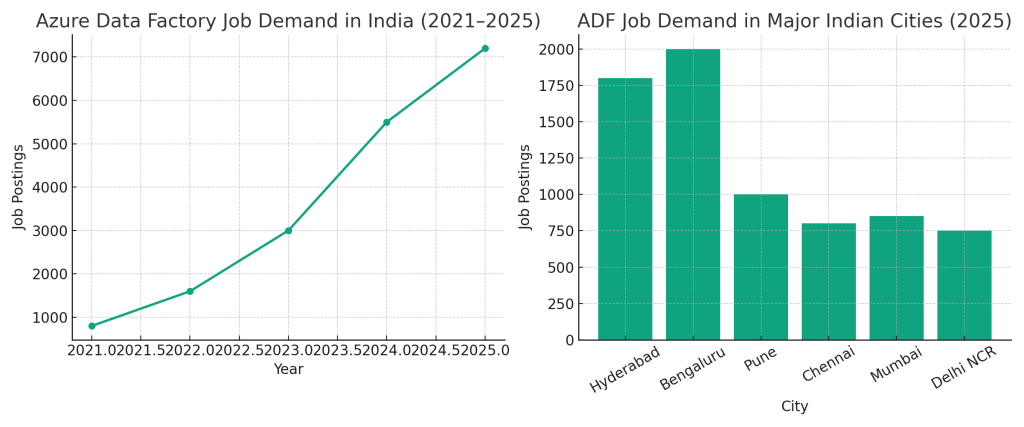
Here are the two graphs :
- India-wide Job Trend for Azure Data Factory (2021–2025)
- City-wise Job Demand in 2025 across India’s metro cities:
- Bengaluru and Hyderabad lead the demand.
- Followed by Pune, Chennai, Mumbai, and Delhi NCR.
ADF Architecture vs AWS vs GCP
A table comparing the architecture of Azure Data Factory with its counterparts on Amazon and Google’s cloud platforms. The services I will be comparing are:
- Azure Data Factory (ADF): A cloud-based, serverless tool from Microsoft Azure that helps you build, schedule, and run data pipelines to move and transform data.
- AWS Glue: A fully managed, serverless data integration and ETL (Extract, Transform, and Load) service from Amazon Web Services.
- Google Cloud Dataflow: A fully managed service from Google Cloud that runs data processing pipelines using the open-source Apache Beam framework.
These three services are the primary tools used for building data pipelines and managing data integration workflows on their respective cloud platforms.
Here is a comparison table highlighting the key architectural differences:
Feature | Azure Data Factory (ADF) | AWS Glue | Google Cloud Dataflow |
Core Architecture | A metadata-driven orchestration service that visually creates, schedules, and monitors data pipelines. It doesn’t run the compute itself, but orchestrates compute services like Azure Databricks or Azure Synapse. | A serverless ETL tool that offers a data catalog and automatically manages and scales resources to run jobs using Apache Spark. | One platform that can process both real-time (streaming) and scheduled (batch) data, using the Apache Beam framework. It focuses on the data processing model itself rather than just orchestration. |
Data Processing Model | Primarily focused on data movement and orchestration of data transformations. It uses “Data Flows” for low-code transformations and “Integration Runtimes” to connect and move data. | A dedicated ETL (Extract, Transform, Load) service optimized for Spark-based workloads. It is code-centric, primarily using Python and Scala. | A unified programming model for both batch and stream processing, excelling at real-time data streaming and low-latency processing. |
Integration & Ecosystem | Wide range of pre-built connectors for a hybrid and multi-cloud environment. It integrates deeply with the entire Azure ecosystem (Synapse, Databricks, SQL). | Deeply integrated with AWS services like S3, Redshift, and Athena. It also supports some external data sources. | Works seamlessly with other Google Cloud services such as BigQuery and Cloud Pub/Sub. It is built on the open-source Apache Beam SDK, allowing for portability. |
User Experience | Features a user-friendly, low-code/no-code visual interface for building and managing pipelines, making it accessible to a broader audience. | Offers both a visual interface (Glue Studio) and a code-centric approach for complex transformations, catering more to developers. | More developer-centric, requiring knowledge of the Apache Beam SDK and programming in Java or Python. |
Hybrid Cloud | A significant advantage is its ability to handle hybrid scenarios with its Self-hosted Integration Runtime, allowing secure data movement between on-premises and cloud environments. | Has more limited hybrid capabilities, though it can connect to on-premises databases. | Primarily a cloud-native solution, though it can integrate with on-premises data sources through custom connectors or other services. |
Top Benefits of Using Azure Data Factory Architecture
1. Modular – Easily Add or Remove Components
Azure Data Factory follows a modular design, meaning you can build your pipeline using small, independent parts (called components).
- Want to copy data from a new source? Just add a Copy Activity.
- Want to clean the data? Plug in a Data Flow step.
- Want to call an API? Add a Web Activity.
Why it matters: You don’t have to rebuild the whole pipeline. Just change one part.
Example: A retail company wants to include a new CRM system. Instead of rewriting everything, they just add one extra activity to their existing pipeline.
2. Resilient – Built-In Retry and Error Handling
In real-world data operations, things can go wrong — a file may not arrive on time, or a connection may temporarily fail.
ADF is designed to be resilient:
- Retry policies can be configured for each activity.
- If a step fails, it can be automatically retried multiple times.
- You can set up alerting and failure paths in the pipeline using If Condition or Switch activities.
Why it matters: Your workflows continue running without manual intervention, making it enterprise-ready.
3. Observable – Built-in Monitoring, Logging & Alerts
Keeping track of data pipelines is important — and Azure Data Factory simplifies the process.
- The ADF UI has a monitor tab to track pipeline runs, activity duration, and success/failure status.
- You can enable alerts for failures or delays using Azure Monitor or Log Analytics.
- All logs are available for auditing and debugging.
Why it matters: You can track every pipeline execution, identify bottlenecks, and debug problems quickly.
Example: A data engineer sees that 1,000 rows failed to load due to a type mismatch — logs show exactly where and why it happened.
4. Cost-Optimized – Pay-As-You-Go Billing
ADF is a fully managed PaaS solution, meaning there’s no need to purchase or manage any servers yourself.
You only pay for:
- Pipeline orchestration time (per activity run)
- Data movement volume
- Data Flow compute time (per vCore-hour)
Why it matters: You control your costs. Small workloads stay cheap. Heavy pipelines only cost when they run.
Tip: Use activity concurrency and pipeline chaining to reduce redundant runs.
5. Interoperable – Works Seamlessly with Other Azure Services
ADF is deeply integrated with the Azure ecosystem. It works out of the box with:
- Azure Data Lake (storage and raw data landing)
- Azure Synapse Analytics (data warehousing and analytics)
- Azure Databricks (for machine learning and Spark-based transformations)
- Azure Blob Storage
- Power BI (automated refresh after data load)
Why it matters: You can build end-to-end pipelines — from raw data to dashboards — without leaving Azure.
Example: Use ADF to ingest data → transform it with Databricks → store in Synapse → auto-refresh Power BI dashboards.
Summary Table
Benefit | What It Means | Why It Helps You |
Modular | Add/replace components anytime | Flexible pipelines |
Resilient | Automatic retries and error handling | Reliable automation |
Observable | Real-time logs, monitoring, and alerts | Easy debugging |
Cost-Optimized | Pay only for what you use | Budget-friendly |
Interoperable | Works with other Azure services natively | Build full data solutions |
Top Azure Data Factory Training Institutes in Hyderabad
1. AzureTrainings
AzureTrainings is known for its specialized courses in Microsoft Azure, particularly focused on Azure Data Factory, Synapse, and Data Lake. The training includes hands-on lab sessions, real-world use cases, and practical guidance.
Key Features:
- Focused modules on ADF pipelines and architecture
- Project-based learning with real datasets
- Certification preparation support
- Resume building and interview coaching
- Instructor-led sessions and weekend batch options
Location: Ameerpet
Website: azuretrainings.in
2. Brolly Academy
Brolly Academy offers Azure Data Factory training both online and offline. Their course structure is aligned with the latest Microsoft certifications and industry standards.
Key Features:
- Detailed training on ADF triggers, activities, and dataflows
- Integration with Synapse, Data Lake, and Data Bricks
- Access to live and recorded sessions
- Certification-oriented curriculum
- Placement support for freshers and professionals
Location: Kukatpally, Jntu
Website: brollyacademy.com
3. Kelly Technologies
Kelly Technologies is a trusted name for professional IT training, offering in-depth knowledge of Azure Data Factory, data pipelines, and cloud integration.
Key Features:
- Strong focus on ADF real-time project implementation
- Step-by-step instruction on integration with Azure tools
- Flexible batches for working professionals
- Experienced trainers with Azure certifications
Location: Ameerpet
Website: kellytechno.com
4. Naresh IT
Naresh IT is suitable for beginners seeking affordable and structured training in Azure Data Factory. The institute also provides a broader understanding of the Azure ecosystem.
Key Features:
- Basics to advanced ADF concepts explained clearly
- Good peer-learning environment
- Hands-on lab access and practice exercises
- EMI options available
Location: Ameerpet
Website: nareshit.in
5. Capital Info Solutions
Capital Info Solutions delivers training with a corporate-oriented approach, suitable for professionals aiming to advance in data engineering with Azure.
Key Features:
- Training on advanced features like pipeline orchestration and automation
- Includes Azure DevOps CI/CD integration
- Covers architectural design concepts
- Trainer-led real-time use case discussions
Location: Madhapur
Website: capitalinfosolutions.com

conclusion
- Azure Data Factory is a strong and flexible cloud tool used to create scalable data pipelines for modern data processing. Its architecture is designed to simplify complex data integration across hybrid environments.
- Whether you’re a beginner or an experienced data engineer, learning ADF architecture can take your career to the next level.
- Ready to explore? Start building your first pipeline today or enroll in a hands-on training program to master Azure Data Factory end-to-end.
FAQs about Azure Data Factory Architecture
No, it’s pay-as-you-use. Charges depend on pipeline runs, data volume, and compute.
It’s the engine that performs data movement and transformation.
Yes, using the SSIS IR.
ADF supports over 90 connectors: SQL, Blob, Oracle, SAP, Salesforce, and more.
To store connection info for data sources and destinations.
Yes, using Web Activities.
Graphical interface to design transformations like joins, filters, expressions.
It’s better suited for batch processing. Use Azure Stream Analytics for real-time.
ADF is for orchestration; Databricks is for advanced analytics and ML.
Yes, using Azure DevOps or GitHub.
Yes, Git integration is supported.
Not necessarily. You can use drag-and-drop features.
Microsoft DP-203: Data Engineering on Azure.
Yes, using triggers (time-based or event-based).
Yes, with support for encryption, VNET, and private endpoints.
Microsoft Azure is a trusted cloud platform that’s booming rapidly.
It’s the future — don’t wait. Enroll now!