Azure Data Factory Pipeline
Azure Data Factory Pipeline Activities, Creation & Tutorials

An Overview of Azure Data Factory Pipeline
What actually is a Pipeline in ADF?
- A pipeline in Azure Data Factory is a collection of tasks or steps that are organized to work together to complete a specific job, such as moving data from one place to another or modifying data to prepare it for analysis.
Key Features:
- Activity-Oriented: A pipeline can contain multiple activities, such as data movement, transformation, or execution of stored procedures.
- Reusability: You can create reusable workflows to streamline data integration tasks.
- Trigger Support: Pipelines can be scheduled or triggered by events.
- Integration: Works seamlessly with various data sources, including on-premises, cloud, and third-party services.
- Monitoring: Provides real-time monitoring and logging for troubleshooting and optimization.
What Is Azure Data Factory Pipeline?
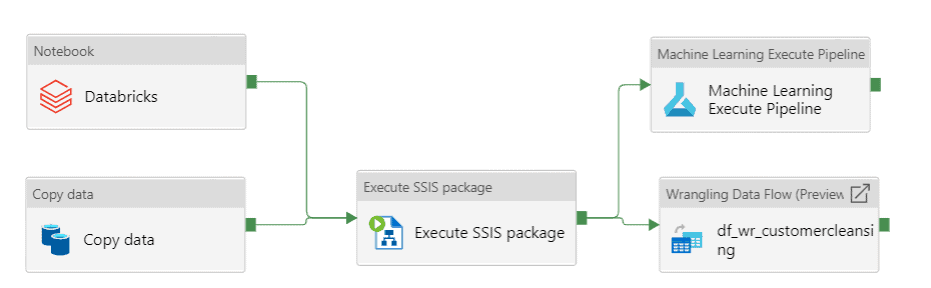
- Azure Data Factory Pipeline is a cloud-based data integration service that enables users to create, schedule, and manage data pipelines.
- It is designed to facilitate the movement of data between various sources and destinations, including on-premises and cloud-based systems.
- With Azure Data Factory Pipeline, you can create complex data integration workflows by using a visual interface or writing code.
- You can also monitor and manage your pipelines in real-time, ensuring that your data is always up-to-date.
- The service supports a wide range of data sources, including on-premises, cloud-based, and big data sources.
- It also supports a variety of data transformation activities, such as mapping, filtering, and aggregation.
- One of the key benefits of Azure Data Factory Pipeline is its flexibility. You can use it to integrate data across different platforms, such as Azure SQL Database, Azure Blob Storage, and Azure Data Lake Storage.
- You can also use it to move data between on-premises and cloud-based systems.
- Another benefit of Azure Data Factory Pipeline is its scalability. You can easily scale up or down your data integration workflows based on your business needs.
- This means that you can process large amounts of data quickly and efficiently without having to invest in expensive hardware or infrastructure.
- Overall, Azure Data Factory Pipeline is a powerful and flexible data integration service that can help you move and transform data across different platforms with ease.
- With its visual interface, code-based authoring, and real-time monitoring capabilities, it is an excellent choice for businesses of all sizes looking to streamline their data integration workflows.
Key components of Azure Data Factory Pipeline
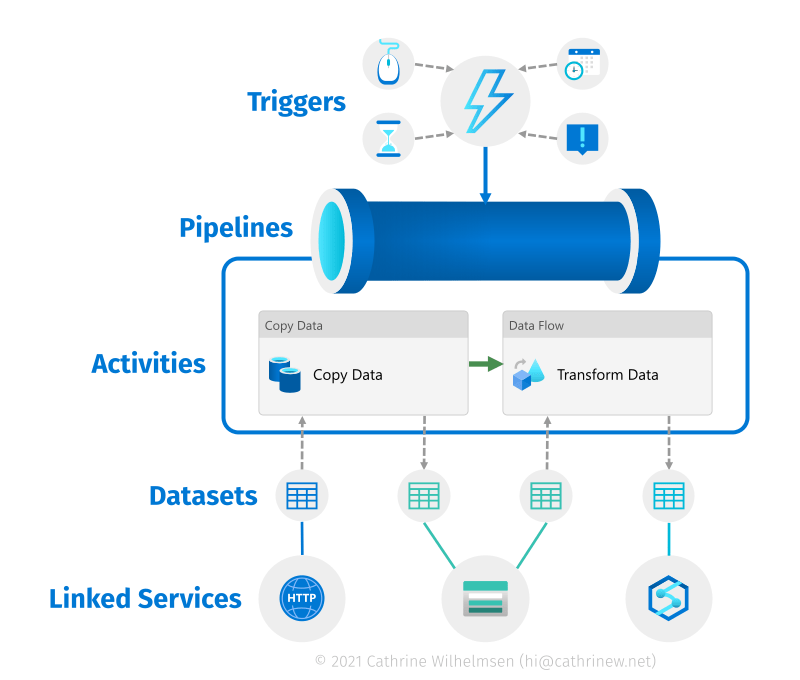
- Data Sources: Azure Data Factory Pipeline supports a variety of data sources, including on-premises, cloud-based, and big data sources. These sources can be connected to the pipeline to extract data for processing.
- Data Destinations: Once the data is extracted, it needs to be loaded into a destination system. Azure Data Factory Pipeline supports a variety of data destinations, such as Azure SQL Database, Azure Blob Storage, and Azure Data Lake Storage.
- Activities: Activities are the building blocks of an Azure Data Factory Pipeline. They are used to define the steps that need to be performed on the data, such as copying data, executing a stored procedure, or transforming data.
- Data Flows: Data flows are used to transform data within the pipeline. They provide a visual interface for defining data transformations, such as mapping, filtering, and aggregation.
- Triggers: Triggers are used to schedule the execution of a pipeline. They allow you to define the frequency and start time of the pipeline execution.
- Integration Runtimes: Integration runtimes are used to connect to the data sources and destinations. They provide a secure and efficient way to move data between different systems.
- Monitoring: Azure Data Factory Pipeline provides real-time monitoring capabilities that allow you to track the progress of your pipeline execution.
Types of Azure Data Factory Pipeline Tools
- Azure Data Factory Pipeline provides a wide range of activities that can be used to perform various tasks during the data integration process.
- These activities can be grouped into the following categories:
- Data Movement Activities: These activities are used to move data between various data stores.
- Azure Data Factory Pipeline provides built-in connectors for various data sources, such as Azure SQL Database, Blob Storage, and Cosmos DB.
- Data Transformation Activities: These activities are used to transform data as it moves through the pipeline.
- Azure Data Factory Pipeline provides a visual interface for building data transformation logic using drag-and-drop components, including data sources, transformations, and sinks.
- Control Flow Activities: These activities are used to control the flow of data through the pipeline. Control Flow Activities include If Condition, For Each, Until,Switch, Wait and Set Variable Activity.
- Types of Control Flow Activities
- There are several Control Flow Activities available in Azure Data Factory Pipeline, including:
- If Condition Activity: This activity is used to evaluate a condition and execute different actions based on the outcome of the evaluation.
- For Each Activity: This activity is used to iterate over a collection of items and perform a set of actions for each item in the collection.
- Until Activity: This activity is used to repeatedly execute a set of actions until a specified condition is met.
- Switch Activity: This activity is used to execute different actions based on the value of a specified expression.
- Wait Activity: This activity is used to pause the execution of the pipeline for a specified amount of time.
- Set Variable Activity: This activity is used to set the value of a variable that can be used in subsequent activities.
- Pipeline Execution Activities: These activities are used to manage the execution of the pipeline. Pipeline Execution Activities include Wait, Set Variable, and Execute Pipeline.
- Azure Function Activities: These activities are used to run custom code using Azure Functions. Azure Functions is a serverless compute service that allows you to run code in response to events, such as data being processed in the pipeline.
- Integration Runtime Activities: These activities are used to manage the integration runtime.
- Integration runtimes are used to connect to different data sources and destinations. Integration Runtime Activities include Start Integration Runtime, Stop Integration Runtime, and Check Integration Runtime Status.
Types of Data Factory Pipeline tools
Azure Data Factory Pipeline is a cloud-based data integration service that enables you to create, schedule, and manage data integration workflows.
There are several tools available in Azure Data Factory Pipeline that you can use to build and monitor your pipelines. Here are some of the types of tools available in Azure Data Factory Pipeline:
- Data Factory Editor: The Data Factory Editor is a web-based graphical user interface (GUI) that allows you to create and manage your data integration workflows. It provides a drag-and-drop interface for building pipelines and activities, as well as a rich set of debugging and monitoring tools.
- Azure Portal: The Azure Portal is a web-based management tool that allows you to manage your Azure resources, including your Azure Data Factory Pipeline. You can use the Azure Portal to create and monitor your pipelines, as well as to manage your data sources and destinations.
- Azure PowerShell: Azure PowerShell is a command-line interface (CLI) that allows you to manage your Azure resources using PowerShell scripts. You can use Azure PowerShell to create and manage your Azure Data Factory Pipeline, as well as to automate your data integration workflows.
- Azure CLI: Azure CLI is a cross-platform command-line interface that allows you to manage your Azure resources using CLI commands. You can use Azure CLI to create and manage your Azure Data Factory Pipeline, as well as to automate your data integration workflows.
- REST API: The Azure Data Factory Pipeline REST API allows you to programmatically create and manage your pipelines. You can use the REST API to automate your data integration workflows, as well as to integrate Azure Data Factory Pipeline with other applications.
How to Create a Pipeline in Azure Data Factory ?
Creating a pipeline in Azure Data Factory involves a few simple steps. By following these steps, you can build and execute data integration workflows to move and transform data between various sources and destinations.
- Create a new data factory: To create a new data factory, go to the Azure portal and search for “Data Factory”. Click on “Add” and follow the prompts to create a new data factory.
- Create a new pipeline: Once you have created a new data factory, click on “Author & Monitor” to open the Azure Data Factory UI. Click on the “Author” tab and then select “New pipeline” to create a new pipeline.
- Add an activity: Once you have created a new pipeline, you can add activities to it. To add an activity, drag and drop it from the toolbox onto the pipeline canvas.
- Configure the activity: Once you have added an activity to the pipeline, you need to configure it. This involves defining the input and output datasets, as well as any other settings required for the activity.
- Add more activities: You can add as many activities as you need to the pipeline. You can also use control flow activities, such as conditional statements and loops, to create more complex workflows.
- Publish the pipeline: Once you have finished building the pipeline, click on “Publish all” to save and publish the changes.
- Trigger the pipeline: To execute the pipeline, you need to trigger it. You can do this manually by clicking on “Trigger now” or you can set up a trigger to run the pipeline on a schedule or in response to an event.
- Monitor the pipeline: Once the pipeline is running, you can monitor its progress by clicking on “Monitor & Manage”. This will show you the status of the pipeline and any errors or warnings that occur.
Advantages of Azure Data Fctory Pipeline
- Scalability: Azure Data Factory Pipeline can easily scale up or down based on your data integration needs. You can add or remove resources as required and pay only for the resources you use.
- Integration: Azure Data Factory enables you to integrate with various data sources, including on-premises and cloud-based systems. This integration is possible due to connectors that support a variety of data sources including Azure Blob Storage and SQL Database
- Automation: Azure Data Factory Pipeline enables you to automate your data integration workflows, reducing manual intervention and allowing you to focus on other critical tasks.
- Flexibility: Azure Data Factory Pipeline supports both code-based and GUI-based workflows, giving you the flexibility to choose the approach that works best for your needs.
- Security: Azure Data Factory Pipeline implements robust security measures to protect your data, including encryption at rest and in transit, role-based access control (RBAC), and more.
- Monitoring: Azure Data Factory Pipeline provides comprehensive monitoring and logging capabilities, allowing you to monitor pipeline executions, diagnose issues, and optimize performance.
- Cost-Effective: Azure Data Factory Pipeline is a cost-effective data integration solution, as it supports pay-as-you-go pricing, which means you only pay for the resources you use.
Disadvantages of Azure Data Factory Pipeline
- You can only create pipelines from notebooks, not from the command-line interface.
- Pipelines do not include all of the functions available in the R language.
- Pipelines are available only in the Enterprise Edition of Azure Databricks.
- Pipelines can only run on Apache Spark and not other libraries like TensorFlow.
- Pipelines are limited in terms of their ability to perform complex tasks like data cleansing, transformations and ETL integration.
- You cannot run a pipeline on an existing dataset but must instead create a new one.
- Pipelines are limited to one processor core, while notebooks can be assigned up to 128 cores.
- Pipelines don’t support Python or Scala.
Limitations of Azure Data Factory Pipeline
- Limited data transformation capabilities: Azure Data Factory Pipeline is primarily designed for data movement and copy operations.
- It has limited capabilities for advanced data transformation and processing tasks such as data cleansing, filtering, and aggregation.
- Limited support for complex workflows: Azure Data Factory Pipeline is best suited for simple workflows with basic dependencies.
- Limited integration with non-Azure services: While Azure Data Factory Pipeline provides integration with various Azure services, it has limited support for non-Azure services.
- Limited debugging capabilities: Debugging Azure Data Factory Pipeline can be challenging. While it provides basic logging and monitoring capabilities, it does not offer advanced debugging features such as breakpoints and step-by-step execution.
- Limited customization options: Azure Data Factory Pipeline has limited customization options for data integration workflows.
- This can be a challenge if you require high-level customizations or tight controls over your workflow execution processes.
Data Transformation and Processing in Azure Data Factory Pipeline
- Data transformation and processing are essential components of any data integration pipeline.
- Azure Data Factory Pipeline provides a wide range of features for transforming and processing data as it moves through the pipeline.
- One of the key data transformation features of Azure Data Factory Pipeline is data flows. Data flows provide a visual interface for building data transformation logic using drag-and-drop components.
- These components include data sources, transformations, and sinks. Data flows can be used to perform tasks such as mapping, filtering, aggregating, joining, and sorting data.
- Another important data transformation feature of Azure Data Factory Pipeline is the ability to run custom code using Azure Functions.
- Azure Functions is a serverless compute service that allows you to run code in response to events, such as data being processed in the pipeline.
- Azure Data Factory Pipeline also provides a wide range of data processing features. For example, it supports parallel processing, which allows you to process large volumes of data quickly and efficiently.
- It also supports data compression, which can reduce the amount of data that needs to be transferred between systems.
- Data transformation and processing are critical components of any data integration pipeline, and Azure Data Factory Pipeline provides a wide range of features to support these tasks.
- By using data flows, custom code, parallel processing, compression, integration runtimes, and monitoring, you can build and manage complex data integration workflows with ease.
Scheduling and Monitoring Azure Data Factory Pipeline
- Azure Data Factory’s Pipeline provides a variety of features for scheduling and monitoring your data integration workflows.
Scheduling:
- Azure Data Factory Pipeline provides various scheduling options to automate the execution of your data integration workflows.
- You can schedule pipelines to run on a specific date and time or on a recurring basis, such as every hour, day, or week.
- You can also use event-based triggers to start a pipeline when a specific event occurs, such as when new data is added to a storage account.
- Azure Data Factory Pipeline provides a flexible scheduling framework that allows you to set up complex workflows with dependencies between pipelines.
- For example, you can set up a pipeline that only runs when another pipeline has completed successfully.
Monitoring:
- Azure Data Factory Pipeline provides real-time monitoring and logging capabilities that allow you to track the progress of your data integration pipelines and troubleshoot any issues that arise.
- You can monitor the status of your pipelines, activities, and data flows, as well as view detailed logs and metrics for each run.
- Azure Data Factory Pipeline also provides alerts and notifications that can be configured to notify you when a pipeline fails or when a specific condition is met.
- You can set up alerts for various metrics, such as the number of rows processed, the execution time, and any errors that occurred.
- In addition, Azure Data Factory Pipeline integrates with Azure Monitor, which provides a centralized monitoring solution for all your Azure resources.
- Azure Monitor allows you to monitor and analyze performance, collect logs and metrics, and set up alerts and notifications for all your Azure resources, including Azure Data Factory Pipeline.
- By using scheduling options, monitoring capabilities, alerts, and notifications, you can automate and manage your data integration workflows with ease.
Conclusion
- In conclusion, Azure Data Factory Pipeline is a powerful data integration solution that provides numerous benefits for organizations looking to integrate and manage their data in the cloud.
- It offers scalability, integration, automation, flexibility, security, monitoring, and cost-effectiveness, making it an ideal choice for many data integration use cases.
- However, it is essential to be aware of its limitations and disadvantages, such as limited data transformation capabilities, limited support for complex workflows, and limited integration with non-Azure services.
- Despite its limitations, Azure Data Factory Pipeline has proven to be an effective solution for organizations looking to streamline their data integration workflows.
- It enables users to automate their data integration workflows, reducing the need for manual intervention and allowing organizations to focus on other critical tasks.
- Overall, Azure Data Factory Pipeline is an excellent choice for organizations looking to integrate and manage their data in the cloud.
- It offers a wide range of benefits that can help organizations streamline their workflows, reduce costs, and improve data security.

FAQ'S about Azure Data Factory Pipeline;
Azure Data Factory Pipeline is a cloud-based data integration service that enables data movement and transformation between various data sources and destinations.
Azure Data Factory Pipeline supports a wide range of data sources and destinations, including:
- Azure Blob Storage
- Azure Data Lake Storage
- Azure SQL Database
- Azure SQL Data Warehouse
- Azure Synapse Analytics
- Azure Table Storage
- FTP
- HTTP
- SFTP
- Oracle
- MySQL
- PostgreSQL
- Salesforce
- Google Analytics
Yes, Azure Data Factory provides built-in monitoring and logging capabilities that allow you to monitor the performance of your pipelines in real-time.
You can deploy your Azure Data Factory Pipeline using the Azure portal, Azure PowerShell, Azure CLI, or Azure DevOps. The deployment process involves packaging your pipeline into an ARM template and deploying the template to your Azure environment.
Azure Data Factory Pipeline supports a variety of security features, including Azure Active Directory authentication, encryption of data in transit and at rest, and role-based access control.