Azure Data Factory Interview Questions

Topics included:
Additional resources:
Top 30+ Azure Data Factory Interview Questions for freshers
1. What do we need Azure Data Factory for?
- Data is the core of a business, be it a million dollar company or a small startup, you require access to a data source that’s reliable, secure, and easily accessible.
- With Azure Data Factory, Microsoft has given us a powerful data integration solution that lets you build and deploy data transformations in minutes, rather than longer hours.
- It allows you to quickly and easily connect to and work with any data source and is designed to help you automate and orchestrate your data integration tasks. You can quickly and easily transform data from one format into another, making work processes less complicated.
2. What is Azure Data Factory?
- Azure data factory is a fully managed service for data integration, data transformation, and data warehousing. Azure data factory can be used to connect to on-premises databases, on-premises data warehouses, cloud services, and other services.
- With ADF, you can easily create, manage, and orchestrate a wide range of data integration scenarios. it also provides a visual interface for data movement, allowing you to build workflows with ease.
3. Define Integration Runtime and its types.
- The integration runtime in Azure Data Factory is an infrastructure that enables you to perform data integration, transformation, and loading in an automated way. There are 3 types of Integration Runtime –
- Azure Integration Runtime – Azure Integration Runtime (AIR) is an integration platform that allows developers to automate the process of moving data between on-premises data sources and cloud-based data stores.
- Self Hosted Integration Run Time – It is a software with the same code as Azure Integration Run Time, and can be installed on on- premises systems or over virtual networks in virtual machines.
- Azure SSIS Integration Runtime – Azure SSIS integration runtime is a component that provides a set of services that enable you to manage the lifecycle of packages that you import into an SSIS package. It is a service that provides a managed environment for executing packages that were imported into Azure Data Factory.
4. Is there a limit on the number of integration runtimes?
- There is no given limit on the number of integration runtimes.
- There is however a limit on the number of VM cores that can be used by the integration runtime per subscription for SSIS package execution.
5. What do you mean by Blob Storage?
- Blob storage is an extremely scalable and low-cost service for storing, processing, and accessing large volumes of unstructured data in the cloud.
- Blob storage can be used for anything from storing large amounts of data to storing images and videos.
- It provides highly efficient access to any type of file, and it is fast and reliable for both block operations and object-level uploads and downloads.
6. What is the difference between Azure data lake and Azure Data warehouse?
- The data lake is the storage solution for big data analytics. It has been used by many companies to store their data in a central location, which can be accessed by multiple applications.
- The data warehouse is a more powerful version of the data lake. It’s designed to store and visualize large volumes of data and can be used for ETL (Extract, Transform and Load) operations.
7. What are the major concepts of Azure Data Factory?
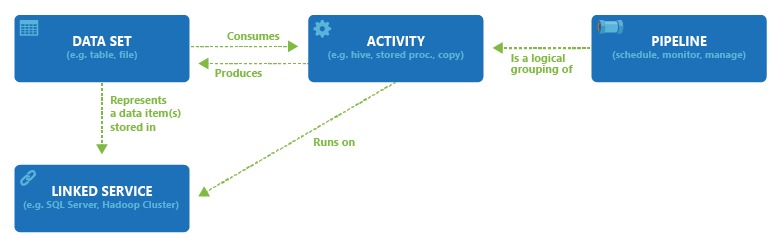
Some of the concepts of ADF are –
- Linked Services – The linked service feature allows you to connect two or more data sources together and run a workflow using the data from one source as input, they can also be shared across multiple resources.
- Pipelines – A pipeline is a group of objects or processes that pass information from one object to another. Pipelines are used in the ADF to pass messages between objects.
- Activities – Activities are the processing steps in a pipeline that will eventually be used for metamorphosis.
- Datasets – A dataset is a collection of data that can be used in a data flow activity. You can use a dataset in a data flow activity to define the source or destination for the data in your data flow.
8. How do I schedule a pipeline?
- The scheduler trigger is the simplest way to schedule a pipeline. It allows you to create a pipeline with a specified start time and duration.
- It can be triggered by a time window, which means that it will start when the specified time window ends.
9. What are the different types of triggers that are supported by Azure Data Factory?
The types of triggers that are supported by Azure Data Factory are –
- Tumbling Window Trigger: A tumbling window trigger is a time-based event that occurs when you want to activate a workflow. The tumbling window trigger can be set to execute a workflow at a specified interval, or based on a specified condition.
- Event-based Trigger: These workflows can be triggered by events such as file creation, changes in a database, or even changes in a blob.
- Schedule Trigger: Schedule triggers allow you to automate some of your Azure Data Factory (ADF) workflows.
10. What are the cross-platform SDKs in Azure Data Factory?
The rich set of SDKs provided by ADF allow us to write, manage, and watch pipelines by applying our favorite IDE. Some of the well-known cross-platform SDKs in Azure Data Factory for advanced users are :
- Python SDK
- PowerShell SDK
- .NET SDK
- Java SDK
- C# SDK
11. Differentiate between Data Lake Storage and Blob Storage?
| Data Lake Storage | Blob Storage |
| Data Lake is an online data storage service in Azure that is used for storing large amounts of data in a single location. | Blob storage is used for storing files and static content like images, videos, etc. |
| It follows a hierarchical file system. | It follows an object store with a flat namespace. |
| Data is stored as files that are present inside folders. | Data is stored in storage accounts in the form of containers. |
| It can be used to store Batch, interactive, stream analytics, and machine learning data. | You can store text files, videos, binary data, media storage for streaming and general purpose data. |
12. How to create an ETL process in Azure Data Factory?
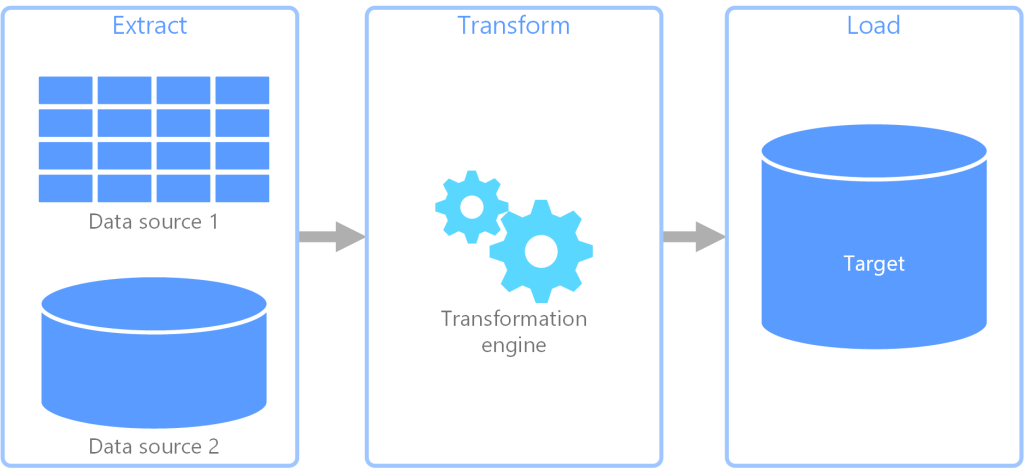
- First, we have to create a service for a linked data store, an SQL Server Database.
- Suppose that we have a car dataset.
- We can create a linked service for the destination data store for this car’s dataset, which is Azure Data Lake.
- Now, we have to create a data set for Data Saving.
- After that, create a Pipeline and Copy Activity.
- In the last step, insert a trigger and schedule your pipeline.
13. Differentiate between the Mapping data flow and Wrangling data flow transformation activities in Adf?
- The Mapping data flow activity transforms one or more source datasets into a single destination dataset while the Wrangling data flow activity transforms one or more source datasets into multiple destination datasets.
14. Which Data Factory version is used for creating data flows?
- Data Factory V2 version is used to create data flows.
15. Can we pass parameters to a pipeline run?
- Yes, we can pass parameters to a pipeline run. A pipeline run is an activity that will be performed by a user, such as a data transformation or data ingestion, and it has a name and a description.
- Pipeline runs can be created from pipelines or they can be executed manually.
16. What are the two levels of security in ADLS Gen2?
- Role-Based Access Control – It includes built-in azure rules such as reader, contributor, owner or customer roles. It is specified for two reasons. The first is, who can manage the service itself, and the second is, to permit the reasons is to permit the users built-in data explorer tools.
- Access Control List – An ACL is a set of rules that can be applied to a resource, such as a directory, file, or database. The rules can be used to specify who can perform actions on the resource, and when those actions can take place.
17. What are the two types of compute environments that are supported by Data Factory?
- On-demand compute environment – On-Demand Compute Environment (ODCE) provides a set of tools that enable you to build, manage, and operate a fully managed cloud service that provides compute resources as a service.
- Bring your own environment – It is a service in Azure that allows you to run your own cloud-based data warehouse wherein you can manage the compute environment with ADF.
18. Define Azure SSIS Integration Runtime.
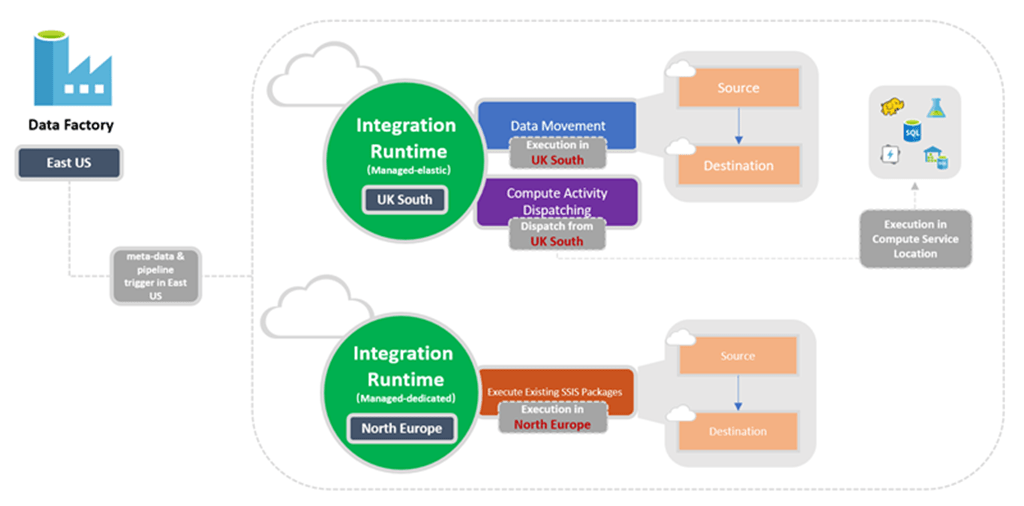
- Azure SSIS Integration Runtime is an integration runtime in Azure Data Factory that provides access to the SSIS Integration Services (SSIS) language from within Azure Data Factory.
- It allows you to run SSIS packages and scripts from within your data factory pipelines.
19. What do you mean by Azure Table Storage?
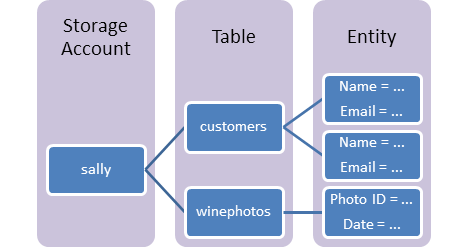
- Azure Table Storage helps to store structured data in the cloud, allowing the data to be accessed from any device.
- It makes it easy to store and access data in the cloud and is ideal for storing large amounts of structured and semi-structured data.
20. Is Azure Data Factory ETL or ELT tool?
- Azure Data Factory (ADF) is a cloud service that helps you automate, orchestrate, and manage data warehouse workloads and supports both ETL and ELT.
21. What separates Azure Data Factory from the conventional ETL tools?
- When it comes to big data analytics, many companies are still using traditional ETL tools like Informatica and Talend.
- ETL tools were designed for batch processing and they’re not optimized for real-time processing.
- These limitations make them a poor choice for big data analytics.
- With the help of Azure Data Factory, organizations can use the power of the cloud to perform a variety of data transformations and extractions, as well as load data into databases and other systems.
22. What is the role of Linked services in Azure Data Factory?
- Linked services are used to connect Azure Data Factory with on-premises or cloud-based systems.
- It provides a mechanism for connecting Azure Data Factory to external systems.
23. What are ARM Templates in Azure Data Factory and what is it used for?
- An Azure Resource Manager template is a JSON (JavaScript Object Notation) file that defines the configuration of a specific resource in Azure.
- The templates are used to deploy the resources in Azure and contain the same code as the pipeline.
- You can use ARM templates to move your application to a new server without having to manually install any software on the server.
- In addition, you can use ARM templates to deploy a new version of your application without having to redeploy the entire application.
24. Which three activities can you run in Microsoft Azure Data Factory?
The activities supported by ADF are data movement, transformation, and control activities.
- Data movement – Azure Data Factory is a service that enables you to easily automate the process of moving data from one storage account to another.
- Transformation – It allows you to perform data transformation and transformation operations like data extraction, data loading, data manipulation, and data joining.
- Control Flow activities – They are responsible for managing the flow of all the activities in a pipeline.
25. Which activity should you use if you want to use the output by executing a query?
- The Look-up activity can be used if you want to use the output by executing a query.
- The output can be an array of attributes or even a single value.
26. Have you ever used Execute Notebook activity in Data Factory? How to pass parameters to a notebook activity?
- Yes, I have executed notebook activity in the data factory.
- We can pass parameters to a notebook activity with the help of the base Parameters property.
- default values from the notebook are executed if and when the parameters are not specified in the activity.
27. Can you push code and have CI/CD in ADF?
- Data Factory fully supports CI/CD for data pipelines using Azure DevOps and GitHub.
- This allows the ETL process to be developed and deployed in stages before releasing the finished product.
- Once the raw data is refined into a ready-to-manipulate, consumable format, load the data into Azure Data Warehouse or Azure SQL Azure Data Lake, Azure Cosmos DB, or other analytics engine that your organization can reference from business intelligence tools.
28. What are variables in Azure Data Factory?
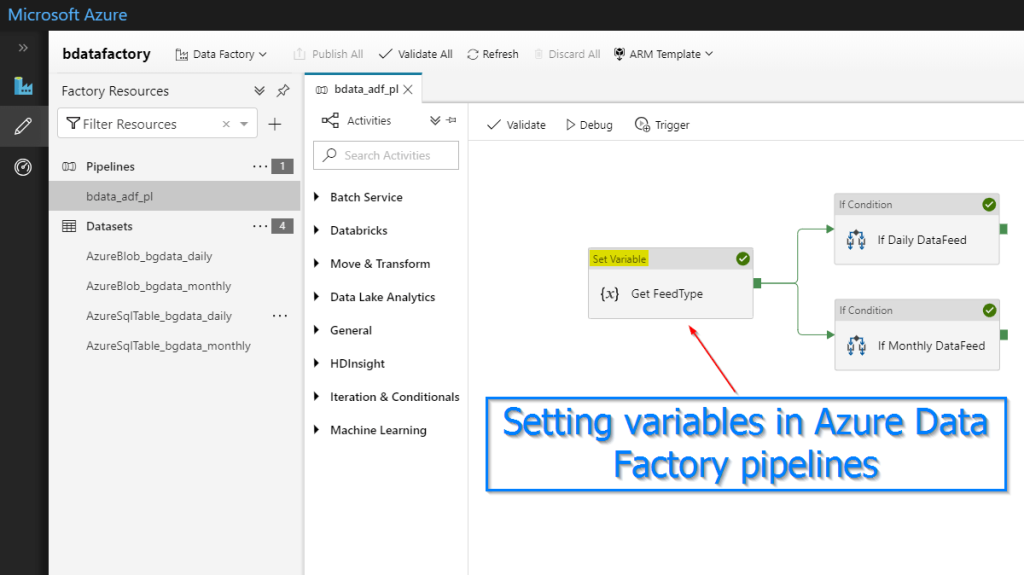
- Variables in Azure Data Factory pipelines provide the ability to store values.
- They are used for similar reasons as variables in any programming language and can be used within a pipeline.
- Set Variable and Add Variable are two activities used to set or manipulate the value of a variable. A data factory has two types of variables:
i) System variables:
These are fixed variables from the Azure pipeline.
ii) User variables:
User variables are manually declared in your code based on your pipeline logic.
29. What do you understand by copy activity in the azure data factory?
- Copy Activity is one of the most popular and used activities in Azure Data Factory.
- This is used for ETL or lift and shift to move data from one data source to another.
- You can also perform transformations while copying data.
- For example, let’s say you are reading data from a txt/csv file that contains 12 columns.
- However, when writing to the target data source, only seven columns should be preserved.
- You can transform this to send only the required number of columns to the target data source.
30. Elaborate on the Copy activity?
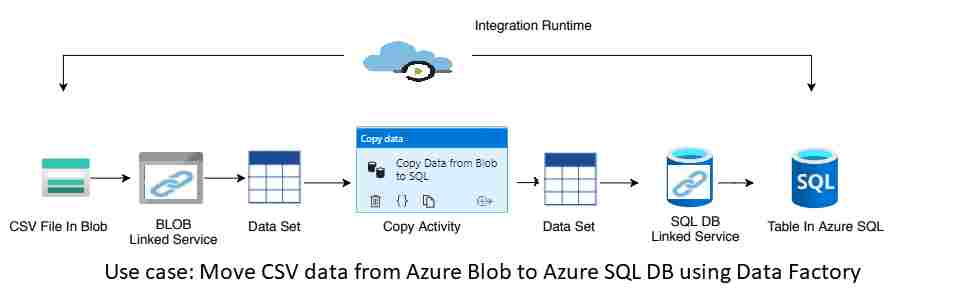
- Copy activity follows these high-level steps:
- Read data from the source data store.
- Perform the following tasks on the data:
- Serialization/Deserialization
- Compression/Decompression
- Column Mapping
- Write data to target data store or sink.
Top 20+ Azure Data Factory Interview Questions for 2+ years experience
31. What are the different activities you have used in Azure Data Factory?
Here you can share some of the most important features if you have used them in your career, whether it is your work or a university project. Here are some of the most used functions:
- The Copy Data function allows you to copy data between datasets.
- ForEach function for a loop.
- Get a metadata function that can provide metadata from any data source.
- Define variable activity to define and initialize variables on the pipeline.
- Search function to search for values from table/file.
- The wait function waits a certain amount of time before or between pipeline operations.
- The validation function checks the existence of files in the data set.
- Web Activity to call a custom REST endpoint from the ADF pipeline.
32. When would you choose to use Azure Data Factory?
- When you need to manage a large number of data sources and data flows, Azure Data Factory is the right choice for you.
- It can help you automate tasks like ETL, data processing, data migration, data integration, and data preparation.
33. What is the purpose of Lookup activity in the Azure Data Factory?
- In the ADF pipeline, the Lookup activity is commonly used for configuration lookup purposes, and the source dataset is available. Moreover, it is used to retrieve the data from the source dataset and then send it as the output of the activity. Generally, the output of the lookup activity is further used in the pipeline for taking some decisions or presenting any configuration as a result.
- In simple terms, lookup activity is used for data fetching in the ADF pipeline. The way you would use it entirely relies on your pipeline logic. It is possible to obtain only the first row, or you can retrieve the complete rows depending on your dataset or query.
34. Is it possible to calculate a value for a new column from the existing column from mapping in ADF?
- We can derive transformations in the mapping data flow to generate a new column based on our desired logic. We can create a new derived column or update an existing one when generating a derived one. Enter the name of the column you’re creating in the Column textbox.
- You can use the column dropdown to override an existing column in your schema. Click the Enter expression textbox to start creating the derived column’s expression. You can input or use the expression builder to build your logic.
35. List the differences between Azure HDInsight and Azure Data Lake Analytics?
Azure HDInsight | Azure Data Lake Analytics |
Azure HDInsight is a Platform as a service | Azure Data Lake Analytics is Software as a service. |
If you want to process the data in Azure HDInsight, you must configure the cluster with predefined nodes. You can also process the data by using languages like pig or hive. | In Azure Data Lake Analytics, we have to pass the queries written for data processing. The Azure Data Lake Analytics further creates compute nodes to process the data set. |
Since the clusters are configured with Azure HDInsight, we create and control them as we want. It also facilitates users to use Spark and Kafka without restrictions. | Azure Data Lake Analytics does not provide so much flexibility in configuration and customization, but Azure manages it automatically for its users. Additionally, it also facilitates users to use USQL taking advantage of .net for processing data. |
36. Can we define default values for the pipeline parameters?
- Yes, we can easily define default values for the parameters in the pipelines.
37. Can an activity in a pipeline consume arguments that are passed to a pipeline run?
- Every activity within the pipeline can consume the parameter value passed to the pipeline and run with the @parameter construct.
38. How to execute an SSIS package in Adf?
- We have to create an SSIS IR, and an SSISDB catalog hosted in Azure SQL Database or Azure SQL Managed Instance to execute an SSIS package in Azure Data Factory.
39. Which Data Factory activity can be used to get the list of all source files in a specific storage account and the properties of each file located in that storage?
- Get Metadata activity.
40. Define Azure as PaaS?
- PaaS is a computing platform that includes an operating system, programming language execution environment, database, or web services.
- This type of Azure services are mostly used by developers and application providers.
41. Which Data Factory activities can be used to iterate through all files stored in a specific storage account, making sure that the files smaller than 1KB will be deleted from the source storage account?
- ForEach activity for iteration
- Get Metadata to get the size of all files in the source storage
- If Condition to check the size of the files
- Delete activity to delete all files smaller than 1KB
42. What are the three methods used for executing pipelines?
- Under Debug mode
- Manual execution using Trigger now
- Using an added scheduled, tumbling window or event trigger.
43. Data Factory supports four types of execution dependencies between the ADF activities. Which dependency guarantees that the next activity will be executed regardless of the status of the previous activity?
- Completion dependency.
44. Can we monitor the execution of a pipeline that is executed under the Debug mode?
- The Output tab of the pipeline, without the ability to use the Pipeline runs or Trigger runs under the ADF Monitor window can be used to monitor it.
45. Define datasets in Adf?
- A dataset refers to data that can potentially be used for pipeline activities as outputs or inputs.
- A dataset is the structure of the data within linked stores of data such as files, documents and folders.
- A Microsoft Azure Blob Storage dataset = a folder and the container within Blob Storage from which particular pipeline activities should read data as processing input.
46. What is Microsoft Azure Databricks?
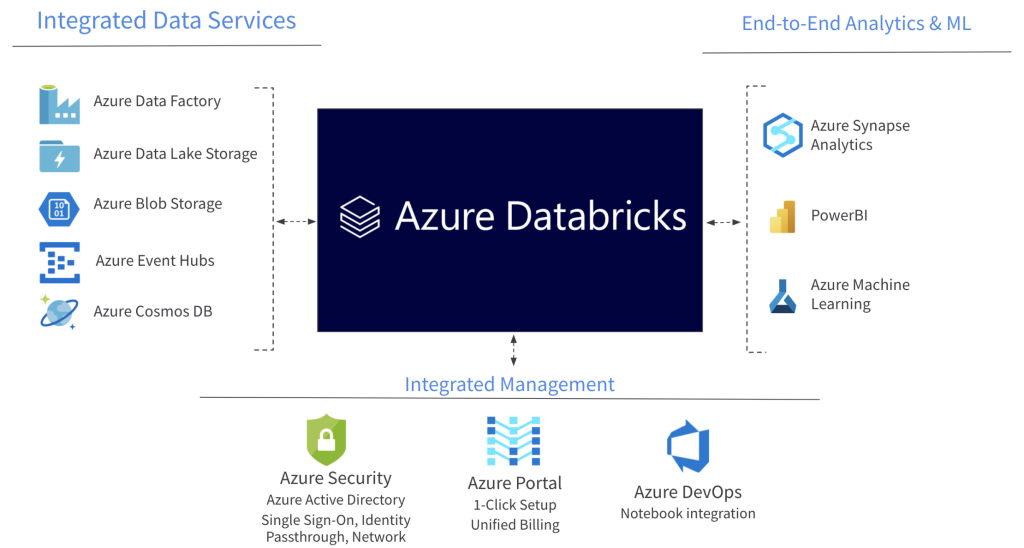
- Databricks refer to a quick, mutual and easy platform based on Apache Spark and optimized for Microsoft Azure.
- Databricks has been designed in collaboration with the Apache Spark founders.
- Additionally, Databricks combines the best features of Azure and Databricks to help users accelerate innovation through a faster setup.
- Business analysts, data scientists and data engineers can work together more easily through these smooth workflows, making for an interactive workspace.
47. Do you require proper coding for ADF?
- Not really, as ADF offers more than 90 built-in connectors to transform data.
48. How can we create Azure Functions?
- Azure Functions are solutions for implementing small lines of functions or code in the cloud.
- With these functions, we can choose preferred programming languages and will only pay for the time the code runs which means that you need to pay per usage.
- It supports a wide range of programming languages including F#, C#, Node.js, Java, Python, or PHP and supports continuous deployment as well as integration.
- It is possible to develop serverless applications through Azure Functions applications.
49. What is Azure Data Lake?
- Azure Data Lake streamlines processing tasks and data storage for analysts, developers, and data scientists.
- It is an advanced mechanism that supports the mentioned tasks across multiple platforms and languages.
- It helps eradicate the barriers linked with data storage, making it simpler to carry out steam, batch, and interactive analytics.
- Features in Azure Data Lake resolve the challenges linked with productivity and scalability and fulfill growing business requirements.
50. What is the data source in the adf?
- The data source is the source that includes the data intended to be used or executed. The data type can be binary, text, csv files, json files, etc.
- It can be in the form of image files, video, audio, or might be a proper database.
- Examples of data source include Azure blob storage,azure data lake storage, Azure sql database, or any other database such as mysql db, etc.
Top 20+ Azure Data Factory Interview Questions for 3+ years experience
51. What does the breakpoint in the ADF pipeline mean?
- Breakpoint is the debug portion of the pipeline. If you wish to check the pipeline with any specific activity, you can accomplish it through the breakpoints.
- Say you are using 3 activities in the pipeline and now you want to debug up to the second activity only. This can be done by placing the breakpoint at the second activity. To add a breakpoint, you can click the circle present at the top of the activity.
52. How to trigger an error notification email in Azure Data Factory?
- We can trigger email notifications using the logic app and Web activity.
- We can define the workflow in the logic app and then can provide the Logic App URL in Web activity with other details.
- You can also send the message also using Web activity after failure or completion of any event in the Data Factory Pipeline.
53. How can we implement parallel processing in Azure Data Factory Pipeline?
- Each Loop Activity in Azure Data Factory provides you with parallel processing functionality.
- For Each Loop Activity, there is a property to process workflow inside the For Each loop in sequential or parallel fashion. The property, is sequential, specifies whether the loop should be executed sequentially or in parallel.
- A maximum of 50 loop iterations can be executed at once in
- With these functions, we can choose preferred programming languages and will only pay for the time the code runs which means that you need to pay per usage.
- It supports a wide range of programming languages including F#, C#, Node.js, Java, Python, or PHP and supports continuous deployment as well as integration.
- It is possible to develop serverless applications through Azure Functions applications.
54. What has changed from private preview to limited public preview in regard to data flows?
- You will no longer have to bring your own Azure Databricks clusters.
- ADF will manage cluster creation and tear-down.
- Blob datasets and Azure Data Lake Storage Gen2 datasets are separated into delimited text and Apache Parquet datasets.
- You can still use Data Lake Storage Gen2 and Blob storage to store those files. Use the appropriate linked service for those storage engines.
55. How can we use code in Data Factory to higher environments?
- Make a feature branch for our code base to be kept.
- Create a request form to merge it when you are sure that the code belongs in the Dev branch.
- Publish the development branch’s code to create ARM templates.
- As a result, code can be promoted to higher surroundings like Staging or Production using an automated CI/CD DevOps pipeline.
56. What are the three tasks that Microsoft Azure Data Factory supports?
- Data Factory supports the following – data movement, transformation, and control activities.
- Movement of data activities: These processes help in transfer of data.
- Activities for data transformation: These activities assist in data transformation as the data is loaded into the target.
- Control flow activities: Control (flow) activities help in regulating any activity’s flow through a pipeline.
57. What activity can be used when you want to use the results from running a query?
- The output of a query or executable execution can be returned by a look-up activity.
- The outcome can be a singleton value, an array of attributes, or any transition or control flow activity like the ForEach activity. These outputs can be used in a subsequent copy data activity.
58. What are the available ADF constructs and how are they useful?
- Parameter: The @parameter construct, each activity in the pipeline can use the parameter value that was passed to it.
- Coalesce: The @coalesce construct can be used in the expressions to handle null values.
- Activity: The @activity construct enables the consumption of an activity output in a subsequent activity.
59. What do you mean by data flow maps?
- Mapping flows of data are data transformations that are visually designed, without having to write any code, data engineers can create data transformation logic using data flows.
- The resulting data flows are carried out in weighted Apache Spark clusters by Azure Data Factory pipelines as activities.
- Utilizing the scheduling, control flow, and monitoring tools already available in Azure Data Factory, data flow activities could be operationalized.
- Data flow mapping offers a completely visual experience without the need for coding. Scaled-out data processing is carried out using execution clusters that are managed by ADF. All of the path optimizations, data flow job execution, and code translation are handled by Azure Data Factory.
60. How are the remaining 90 dataset types in Data Factory used for data access?
- Azure Synapse Analytics, Azure SQL Database delimited text files from such an Azure storage account, or Azure Data Lake Storage Gen2 are all supported as the source and sink data sources by the mapping data flow feature.
- Parquet files from blob storage or Data Lake Storage Gen2 are also supported.
- Data from all other connectors should be staged using the Copy activity before being transformed using a Data Flow activity.
61. Elaborate on ADF's Get Metadata activity.
- Any data in an Azure Data Factory or Synapse pipeline can have its metadata retrieved using the Get Metadata activity.
- The Get Metadata activity’s output can be used in conditional expressions to sample predictions or to consume the metadata in later activities.
- It receives a dataset as input and outputs metadata details.
- The returned metadata can only be up to 4 MB in size.
62. Can ADF pipeline be debugged? How?
- One of the most important components of any coding-related task is debugging, which is necessary to test the software for any potential bugs.
- It also offers the choice of debugging the pipeline without actually running it.
63. How can I copy data from multiple sheets in an Excel file?
- We must specify the name of the sheet from which we want to load data when using an Excel connector inside of a data factory.
- When dealing with data from a single or small number of sheets, this approach is nuanced. However, if we have many sheets (say, 10+), we can use a data factory binary data format plug and point it at the excel file without having to specify which sheet(s) to use.
- The copy activity will allow us to copy the data from each and every sheet in the file.
64. Does ADF facilitate nested looping ?
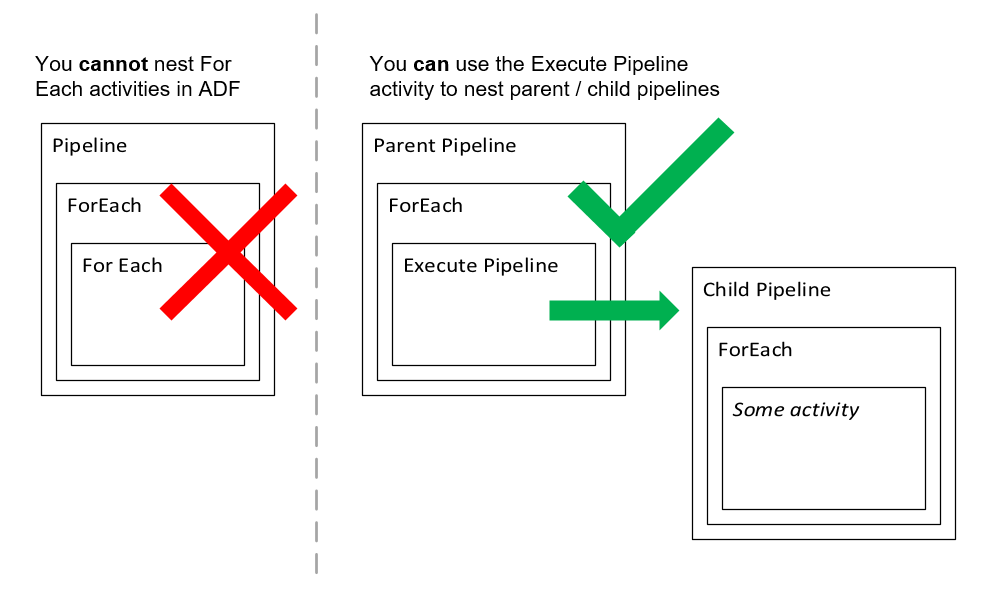
- Yes adf facilitates nested looping.
- Adf does not directly support nested looping for any looping action (for each / until).
- One for each and until loop activities, on the other hand, contain execute pipeline activities that may contain loop activities. In this manner, we can achieve nested looping because when we call the loop activity, it will inadvertently call another loop activity.
65. How can I move multiple tables from one datacenter to another?
A smart way of accomplishing this would be by –
- Having a lookup table or file which lists the tables that need to be copied along with its sources.
- We can then scan the list using the data retrieval activity and each loop activity.
- We can simply employ a copy activity or a mapping data flow inside each loop activity to copy multiple tables to the target datastore.
66. Name a few drawbacks of ADF?
- Adf offers very good data movement and transition functions but it also comes with a few limitations.
- The Looping activities in our pipeline cannot be present in the data factory and requires another solution for it.
- A maximum of 5000 rows can be retrieved at once by the lookup activity. To achieve the same type of organization in the pipeline, we must again combine SQL with another loop activity.
67. Which runtime should be used to copy data from a local SQL Server instance while using Adf?
- We should have the self-hosted assimilation runtime installed on the onsite machine where the SQL Server Instance is offered to host to be able to copy data from an on-premises SQL Database using Azure Data Factory.
68. What is the role of Connected Services in Adf?
In adf, Linked or connected Services are majorly used for –
- Representing a data store, such as SQL Server instance, a file share, or an Azure Blob storage account.
- The underlying VM will carry out the activity specified in the pipeline for Compute representation.
69. Where can I obtain additional information on the blob storage?
Blob Storage lets you store large amounts of data belonging to Azure Objects, like text or binary data. You can retain the classification of the data associated with your application or make it accessible to the public.
The following are some examples of applications of Blob Storage:
- Provides files to a user’s browser in a veridical manner.
- Preserves data by promoting accessibility from a remote location.
- Streams live audio and video content
70. How can I utilize one of the other 80 dataset types that Data Factory provides to get what I need?
Existing options for sinks and sources for Mapping Data Flow includes –
- The Azure SQL Data Warehouse and the Azure SQL Database
- Specified text files from Azure Blob storage or Azure Data Lake Storage Gen2
- Parquet files from either Blob storage or Data Lake Storage Gen2.
You can use the Copy activity to retrieve info from one of the additional connectors and post the data staging process, you must carry out a process known as a Data Flow in order to convert the data.
Top 20+ Azure Data Factory Interview Questions for 5+ years experience
71. Why should we use the Auto Resolve Integration Runtime?
- The runtime environment will make every effort to carry out the tasks in the same physical place as the source of the sink data, or one that is as close as it can get in turn increasing the productivity.
72. What are the advantages of carrying out a lookup in the Adf?
- The Lookup activity is often used for configuration lookup as it has the data set in its initial form. The output of the activity can also be used to retrieve the data from the dataset that served as the source.
- In most cases, the outcomes of a lookup operation are sent back down the pipeline to be used as input for later phases.
73. Does Azure Data Factory offer connected services? If yes, how does it function?
- The connection technique used to join an external source is known as a connected service in ADF and the phrase is used interchangeably.
- It not only serves as the connection string, but also saves the user validation data.
- It can be implemented in two different ways, like –
- ARM approach.
- Azure Portal
74. What are the three most important tasks that can be completed with Microsoft Adf?
Adf makes it easier to carry out three major processes that are moving data, transforming data, and exercising control.
- The operation known as data movement does exactly what the name suggests, which is to facilitate the flow of data from one point to another.
Ex- Information can be moved from one data store to another using Data Factory’s Copy Activity.
- Data transformation activities refers to operations that modify data as it is being loaded into its final destination system.
Ex- Azure Functions, Stored Procedures, U-SQL are a few examples. .
- Control (flow) activities, is to help regulate the speed of any process that is going through a pipeline.
Ex- Selecting the Wait action will result in the pipeline pausing for the amount of time that was specified.
75. What are the steps involved in an ETL procedure?
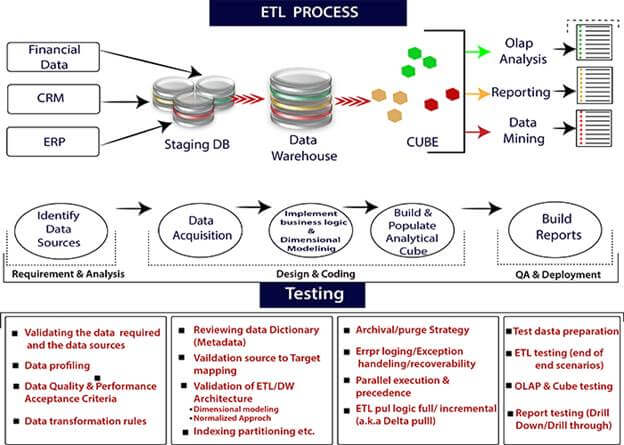
The ETL (Extract, Transform, Load) technique consists of 4 main steps.
- Establishing a link to the data source (or sources) is the initial stage. Then the information is collected and transferred to either a local database or a crowdsourcing database, which happens to be the next step in the process.
- Making use of computational services includes activities such as transforming data by utilizing HDInsight, Hadoop, Spark, and similar tools.
- Sending information to an Azure service, such as a data lake, a data warehouse, a database, Cosmos DB, or a SQL database. This can also be achieved by using the Publish API.
- Azure Data Factory makes use of Azure Monitor, API, PowerShell, Azure Monitor logs, and health panels on the Azure site to facilitate pipeline monitoring.
76. Did you experience any difficulty while migrating data from on-premises to the Azure cloud via Data Factory?
- Within the context of our ongoing transition from on-premises to cloud storage, the problems of throughput and speed have emerged as important obstacles.
- When we attempt to duplicate the data from on-premises using the Copy activity, we cannot achieve the throughput that we require.
The configuration variables that are available for a copy activity make it possible to fine-tune the process and achieve the desired results.
- If we load data from servers located on-premises, we should first compress it using the available compression option before writing it to cloud storage, where the compression will afterwards be erased.
- After the compression has been activated, ii) it is imperative that all of our data be quickly sent to the staging area. Before being stored in the target cloud storage buckets, the data that was transferred might be uncompressed for convenience.
- Copying Proportion, The use of parallelism is yet another alternative that offers the potential to make the process of transfer more seamless. This accomplishes the same thing as employing a number of different threads to process the data and can speed up the rate at which data is copied.
- Because there is no one size that fits all, we will need to try out a variety of different values, such as 8, 16, and 32, to see which one functions the most effectively.
- It may be possible to hasten the duplication process by increasing the Data Integration Unit, which is roughly comparable to the number of central processing units.
77. What are the limitations placed on ADF members?
Adf offers tools for transmitting and manipulating data that are found in its feature set but with a few limitations.
- The data factory does not allow the use of nested looping activities, any pipeline that has such a structure will require a workaround in order to function properly. Here is where we classify everything that has a looping structure: actions involving the conditions if, for, and till respectively.
- The lookup activity is capable of retrieving a maximum of 5000 rows in a single operation at its maximum capacity. To reiterate, in order to implement this kind of pipeline design, we are going to need to use some additional loop activity in conjunction with SQL with the limit.
- It is not possible for a pipeline to have more than forty activities in total, and this number includes any inner activities as well as any containers. To find a solution to this problem, pipelines ought to be modularized with regard to the number of datasets, activities, and so on.
78. Can Data Factory be integrated with Machine learning data?
- The machine learning model can be trained with the data from the pipelines and that can be published as a web service.
79. Define Azure SQL database? Can it be integrated with Data Factory?
- Azure SQL Database is an up-to-date, fully managed relational database service that is built for the cloud, primarily for storing data.
- You can easily design data pipelines to read and write to SQL DB using the Azure data factory.
80. Can SQL Server instances be hosted on Azure?
- Azure SQL Managed Instance is the intelligent, scalable cloud database service that combines the broadest SQL Server instance or SQL Server database engine compatibility.
- It comes with all the benefits of a fully managed platform as a service.
81. What is Azure Data Lake Analytics?

- Azure Data Lake Analytics is an on-demand analytics job service that simplifies the process of storing data and processing big data.
82. What are the major differences between SSIS and Azure Data Factory?
Azure Data Factory (ADF) | SQL Server Integration Services (SSIS) |
ADF is a Extract-Load Tool | SSIS is an Extract-Transform-Load tool |
ADF is a cloud-based service (PAAS tool) | SSIS is a desktop tool (uses SSDT) |
ADF is a pay-as-you-go Azure subscription. | SSIS is a licensed tool included with SQL Server. |
ADF does not have error handling capabilities. | SSIS has error handling capabilities. |
ADF uses JSON scripts for its orchestration (coding). | SSIS uses drag-and-drop actions (no coding). |
83. What do you mean by parameterization in Azure?
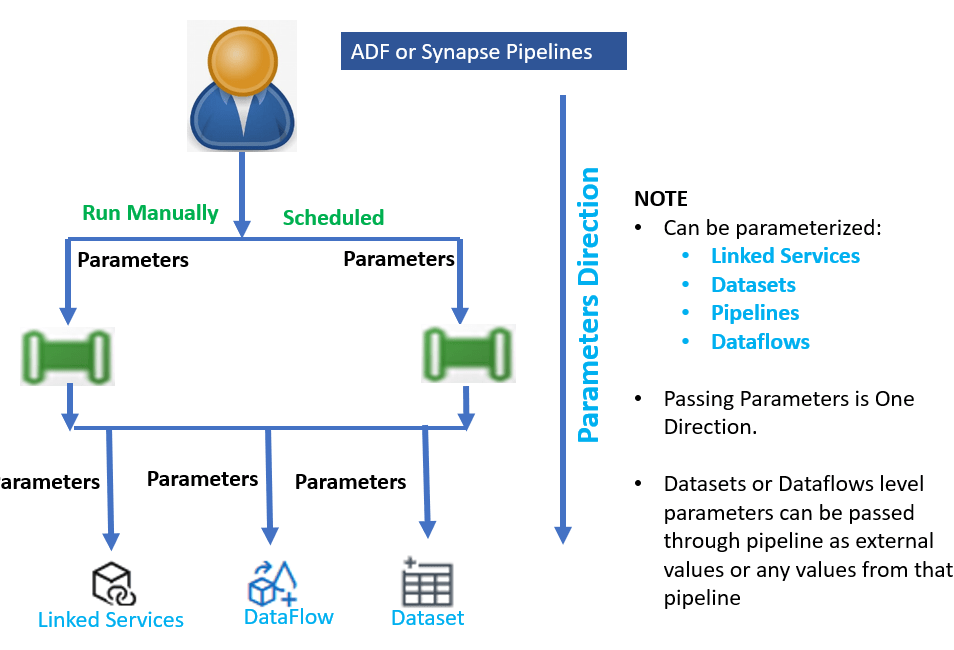
- Parameterization allows us to provide the server name, database name, credentials, and so on while executing the pipeline.
- It allows us to reuse rather than building one for each request.
- Parameterization in Adf is crucial in designing and reusing while reducing the solution maintenance costs.
84. Can we write attributes in cosmos DB in the same order as specified in the sink in ADF data flow?
- Each document in Cosmos DB is stored as a JSON object, which is an unordered set of name or value pairs. Hence, the order cannot be guaranteed.
85. What are the major benefits of Cloud Computing?
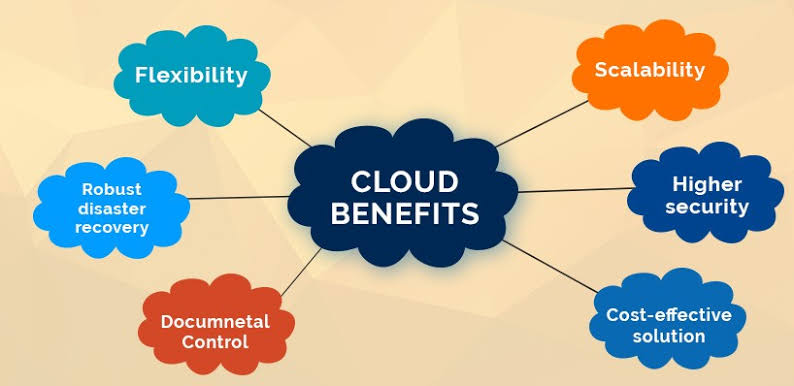
Some of the advantage of Cloud computing are –
- Flexibility
- Scalability
- Security
- Cost effective solution
- Latency
- Documental control
- Robust disaster recovery
86. Can you remove data sets in bulk? If yes, how?
- We can operate the data sets by using PowerShell snippets.
Get-AzureRmDataFactory -ResourceGroupName -Name – Get-AzureRmDataFactoryDataset | Remove-AzureRmDataFactoryDataset
87. Do you think there is demand in ADF?
- Azure Data Factory is a cloud-based Microsoft tool that collects raw business data and transforms it into usable information.
- There is a considerable demand for Azure Data Factory Engineers in the industry.
88. What is NSG?
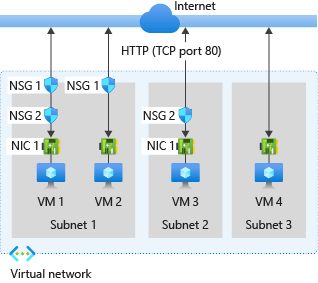
- NSG stands for Network Security Group that has a list of ACL (Access Control List) rules which either allow/deny network traffic to subnets or NICs (Network Interface Card) that are connected to a subnet or both.
- When NSG is linked with a subnet, then the ACL rules are applied to all the Virtual Machines in that subnet. Restrictions of traffic to individual NIC can be done by associating NSG directly to that NIC.
89. What is an azure storage key?
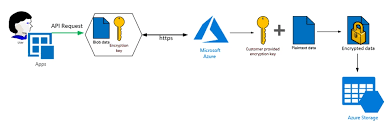
- Azure storage key is used for authentication and validating access for the azure storage services that control access of the data that is based on the project requirements.
- There are 2 types of storage keys that are given for the authentication purpose –
- Primary Access Key
- Secondary Access Key
- The main job of the secondary access key is to avoid downtime of any website or application.
90. What is the service offered by Azure that lets you have a common file sharing system between multiple virtual machines?
- Azure provides a service called Azure File System which is used as a common repository system for sharing the data across the Virtual Machines configured by making use of protocols like SMB, FTPS, NFS, etc.
Top 10+ Azure Data Factory Interview Questions for 7+ years experience
91. What do you know about Azure Scheduler?
- Azure Scheduler helps us to implore a few background trigger events or activities such as calling HTTPS endpoints or presenting a message on the queue on any schedule.
92. What are the types of services offered in the cloud?
IAAS | PAAS | SAAS |
In infrastructure as a service, you get the raw hardware from your cloud provider as a service i.e you get a server which you can configure with your own will. | Platform as a Service, gives you a platform to publish without giving the access to the underlying software or OS. | You get software as a service in Azure, i.e no infrastructure, no platform, simple software that you can use without purchasing it. |
For Example: Azure VM, Amazon EC2. | For example: Web Apps, Mobile Apps in Azure. | For example: when you launch a VM on Azure, you are not buying the OS, you are basically renting it for the time you will be running that instance. |
93. What is cloud computing?
- Cloud computing is basically the use of servers on the internet that helps store, manage and process data.
- The only difference being, instead of using your own servers, you are using somebody else’s servers to accomplish the task by paying them for the amount of time you use it for.
94. What is the Azure Active Directory used for?
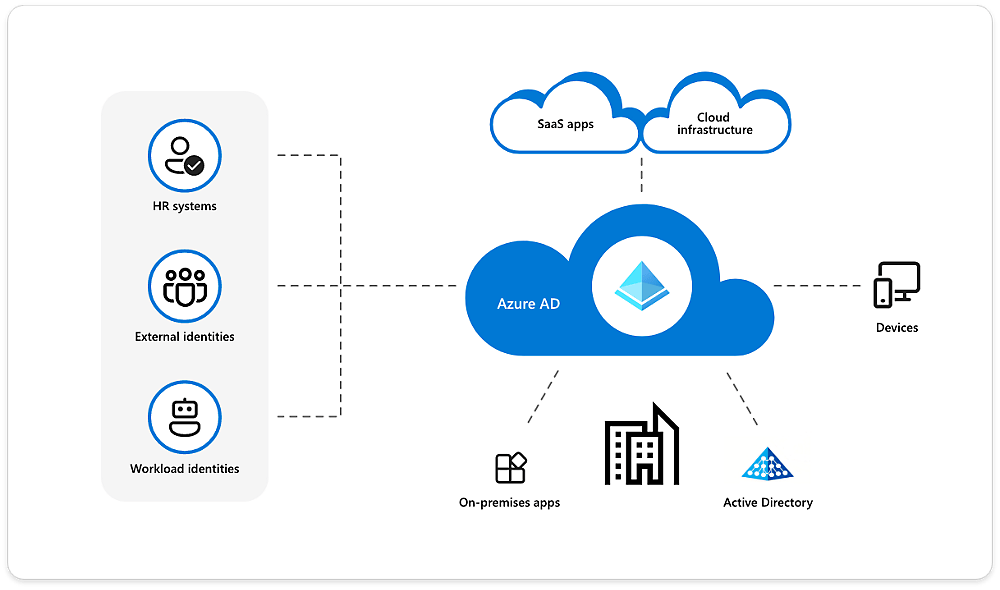
- Azure Active Directory is an Identity and Access Management system.
- It is majorly used to grant access to specific products and services in your network.
95. What do you mean by Azure Redis Cache?
- Redis is an open source (BSD licensed), in-memory data structure store that is used as a database, cache and message broker.
- It is based on the popular open-source Redis cache and gives access to a secure, dedicated Redis cache which is managed by Microsoft.
- It can be accessed from any application within Azure and supports data structures like strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs etc.
96. What do you mean by Azure Search?
- Azure Search can be known as a cloud search-as-a-service solution that offers server and infrastructure management to Microsoft, giving you a ready-to-use service that you can use for your data and then use to add search to your web or mobile application.
- Azure Search lets you add a promising search experience to your applications using a simple REST API or .NET SDK without having to manage search infrastructure or qualifying as an expert in search.
97. What do you know about Azure App Service?
- Azure App Service can be known as a managed Platform-as-a-Service (PaaS) that comes with effective facilities that help with the web, mobile, and integration solutions.
- The Mobile apps in Azure App Service offers an accessible and adaptable application development platform that can be used by Developers and System Integrators as well as mobile engineers.
98. What is profiling meant in Azure?
- Profiling in simple words is a basic procedure that measures and analyzes the performance of an application. It is generally done to ensure that the given application is stable and can maintain and handle heavy traffic.
- Visual Studio also gives us different tools to do it similarly by collecting the information of performance from applications that help with any troubleshooting issues.
- The profiling wizard sets up the execution session and then collects the data of the sample.
- The profiling reports help in the following ways –
- Help Decide long-term strategies within the application.
- Measuring the execution time of every strategy in the call stack
- Assessing allocation of memory.
99. What is the role of the Migration Assistant tool in Azure Websites?
- The Migration Assistant tool will examine and scan our IIS installation to recognize the sites that can be migrated to the cloud while featuring any other components that can’t be migrated or are unsupported on the platform.
- After this process, the migration tool will create sites and databases provided under the respective Azure membership.
100. What do you know about Azure Service Level Agreement (SLA)?
- The SLA makes sure to maintain the access to your cloud service with not less than 99.95 percent of the time, when you send two or more role instances for each role.
- The identification and re-correction activities will also start at 99.9 percent of the time even when a role instance’s procedure isn’t running.
Our Courses




Frequently Asked Questions
The role of an Azure Data Factory Developer is to design, develop, and maintain data integration pipelines in Azure Data Factory, ensure the accuracy and reliability of data, and optimize performance of data processing workflows.
Some common tools and technologies used by Azure Data Factory Developers include Azure Data Factory, Azure Databricks, Azure SQL Database, Azure Data Lake Storage, and Power BI.
Azure Data Factory plays a critical role in data analytics solutions by providing a scalable and reliable platform for data integration and transformation, as well as integrating with other Azure services such as Azure Databricks and Azure Synapse Analytics.
According to Glassdoor, the average salary for an Azure Data Factory Developer in the United States is approximately $95,000 to $145,000 per year, depending on location and experience.
Some key skills for Azure Data Factory Developers include a strong understanding of ETL processes, experience with data integration tools such as Azure Data Factory and Azure Databricks, knowledge of data warehousing and data modeling, and familiarity with SQL and other programming languages.
To become an Azure Data Factory Developer, you typically need to have a strong understanding of data integration concepts, experience with ETL processes and data transformation, and familiarity with Azure services.
Employers may also require specific certifications, such as the Azure Data Engineer Associate certification.
SoAzure Data Factory Developers face a range of challenges, including managing complex data integration scenarios; ensuring data quality and consistency; optimizing performance of processes like ETL or batch analytics jobs on Azure Databricks (new in Spark 2.3) ; troubleshooting issues with workflows caused by late/incorrect inputs
Some best practices for designing data integration pipelines in Azure Data Factory include using a modular design approach, implementing error handling and data validation, optimizing data transfer and transformation operations, and using triggers and scheduling to automate pipeline execution.
The Azure Data Engineer Associate certification is focused on data integration and management, while the Azure Data Scientist Associate certification is focused on data analysis and machine learning.
As more organizations are adopting cloud-based data integration and analytics solutions, there is likely to be continued demand for skilled Azure Data Factory Developers in the coming years.